本新闻中的研究来自于2023年4月发表在《Science Advances》的论文《Does the visual word form area split in bilingual readers? A millimeter-scale 7-T fMRI study》,作者是来自法国NeuroSpin研究所UNICOG研究组的研究学者詹旻野等人。
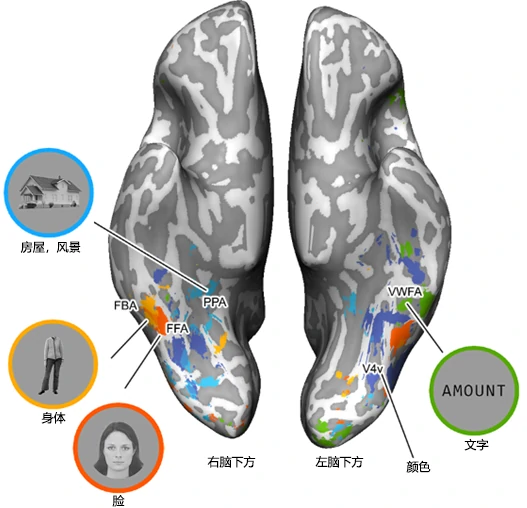
如今,由于工作或者生活等需求,越来越多人能够阅读一种以上的语言。对于不同的字符系统,大脑的处理区域是否相同呢?要回答这个问题,我们首先要知道大脑如何分辨不同的视觉信息,在每个人大脑靠下方的枕叶和颞叶区域(ventral occipito-temporal cortex, VOTC)有一条腹侧通路(ventral pathway),里面有一些脑区分别在处理特定的视觉信息(图1),比如人脸(在FFA脑区处理),风景(在PPA脑区处理),身体(在FBA脑区处理)等。其中也包括专门处理文字的脑区,被称作视觉词形区(visual word form area, VWFA),是由该研究的两位学者Laurent Cohen和Stanislas Dehaene在20多年前发现并命名的。这个区域在阅读过程中形成的,该区域如果受损,病人阅读和理解文字时就会出现障碍。
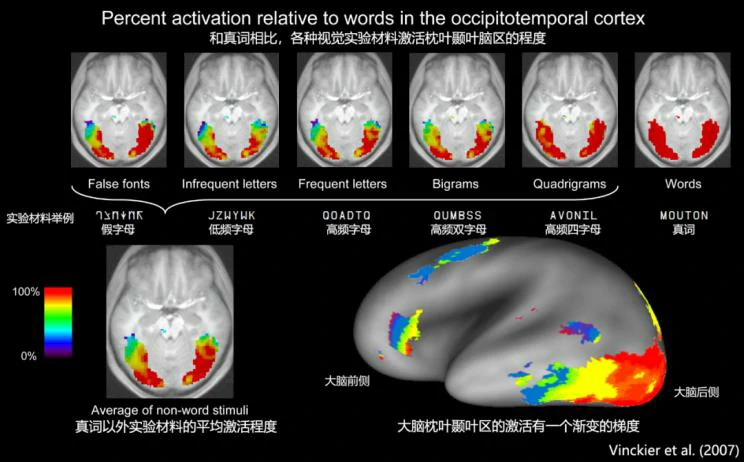
在2007年的一项研究(Vinckier et al. 2007)中发现,在枕叶和颞叶区域有一个渐变的梯度,越往大脑前侧对于真字的激活就越高。但碍于当时的技术限制,实验所采用的是3T fMRI的地磁场和低分辨率(2毫米见方到4毫米见方),得到的实验结果是一大片非常光滑的渐变。
实验一:英法双语的语言处理
为了探究枕叶和颞叶区域是如何处理双语的,以及是否有只处理单种语言的非常精细的小块脑区存在。实验团队在上述实验的基础上,使用了7T的高磁场以及更高分辨率(1.2毫米见方)的fMRI对21位英法双语的志愿者(7位从小就说双语,7位从小先学会英语,7位从小先学会法语)进行实验,来观察他们对于不同视觉信息的脑内活动。首先通过功能定位实验对受试人员脑内的各种视觉处理区域进行定位,找到用于语言处理的区域。

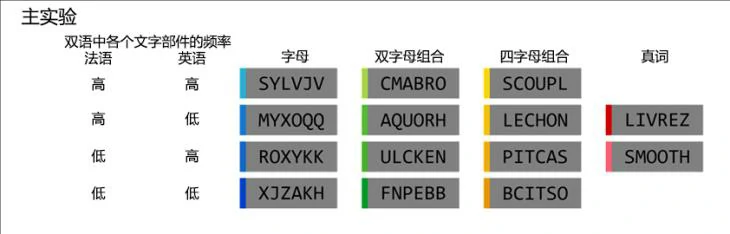
通过功能定位实验定位到用于语言处理的区域后,对受试人员进行主试验。如图为主试验中用到的实验材料,材料中通过控制两种语言中不同使用频率的字母的组合,合成了12个与单词相似的非单词以及1个法语单词和1个英语单词分别呈现给受试人员,然后观察该区域的反应。
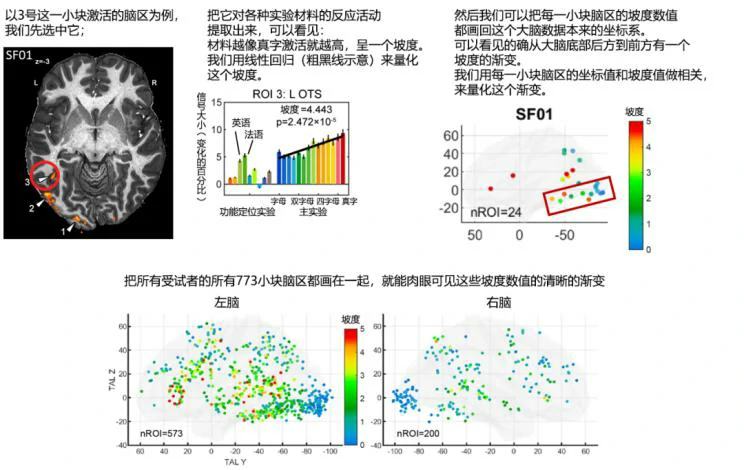
7T高分辨率数据的高精度能够定位到非常精准的小块激活的脑区。通过对于每个小块脑机的单独分析,实验人员发现,实验材料中越像真实的单词,脑区内的活动就越强,并呈现出坡度。同时,实验人员也检查了那些夹杂在语言处理脑区的人脸处理脑区,发现大部分人脸处理脑区都没有出现这种坡度。
虽然观察到了语言处理脑区的活动,但并没有发现只处理单种语言的脑区。实验人员猜测这是由于英语和法语使用了相同的字符,从而导致脑内区别较小。
实验二:中英双语的语言处理
为了验证上述的猜想,实验团队又用相同的实验方法,对10为汉语作为母语的志愿者,使用中文和英文两种字符差异较大的语言进行实验。

在该组实验中,观察到了很多同时处理英语和中文的双语脑区,坡度与渐变与英法语实验中的结果类似。但同时,在10为受试者中的8位观察到了只偏好中文的脑区。这些脑区只有在处理中文时呈现坡度,在英文时则没有坡度,不仅如此,这些脑区在处理人脸信息时,也有较强的活动。
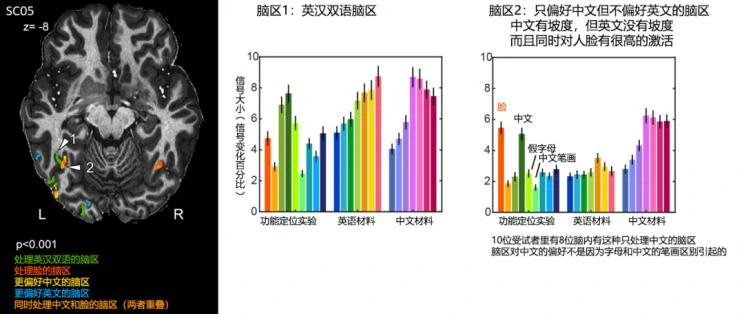
这有可能是因为我们在处理中文的汉字信息时,需要观察整个字的结构,而不仅仅是偏旁部首等部件信息;相似的,在处理人脸时,我们也需要对整张人脸进行处理,而不只是单个的五官。当然,这只是实验人员提出的一种猜想,真正的原因还需要后续的研究加以佐证。但通过这项研究,我们已经知道,在人的大脑中,对于不同的视觉信息,处理的区域也不同。而且,对于使用多种语言的人来说,在处理不同语言时,用于处理的脑区也不相同。相信随着人类科技的发展以及对知识的不断探索,我们也能窥探到更多大脑的秘密。
原文链接
https://www.scholat.com/teamwork/showPostMessage.html?id=13584
https://www.science.org/doi/10.1126/sciadv.adf6140
https://www.sciencedirect.com/science/article/pii/S0896627307004503
https://mp.weixin.qq.com/s/p7dbOF9wySVDz2_hdFy0Gg