导言
凸优化(convex optimization)是最优化问题中非常重要的一类,也是被研究的很透彻的一类。对于机器学习来说,如果要优化的问题被证明是凸优化问题,则说明此问题可以被比较好的解决。在本文中,将为大家深入浅出的介绍凸优化的概念以及在机器学习中的应用。
凸优化简介
上文我们介绍了最优化的基本概念以及梯度下降法。如果对目标函数,优化变量,可行域,等式约束,不等式约束,局部极小值,全局极小值的概念还不清楚,请先阅读那篇文章。
求解一个一般性的最优化问题的全局极小值是非常困难的,至少要面临的问题是:函数可能有多个局部极值点,另外还有鞍点问题。对于第一个问题,我们找到了一个梯度为0的点,它是极值点,但不是全局极值,如果一个问题有多个局部极值,则我们要把所有局部极值找出来,然后比较,得到全局极值,这非常困难,而且计算成本相当高。第二个问题更严重,我们找到了梯度为0的点,但它连局部极值都不是,典型的是x3这个函数,在0点处,它的导数等于0,但这根本不是极值点:
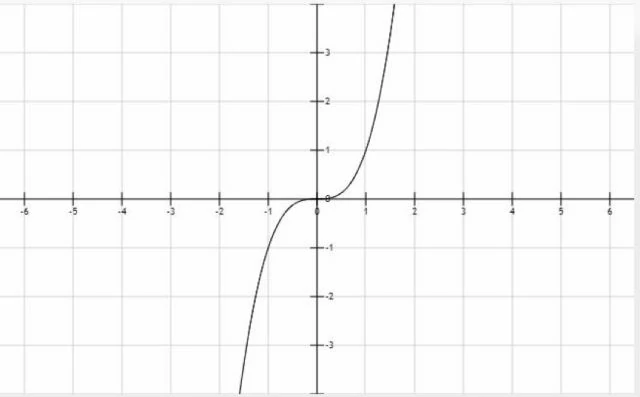
梯度下降法和牛顿法等基于导数作为判据的优化算法,找到的都导数/梯度为0的点,而梯度等于0只是取得极值的必要条件而不是充分条件。如果我们将这个必要条件变成充分条件,即:
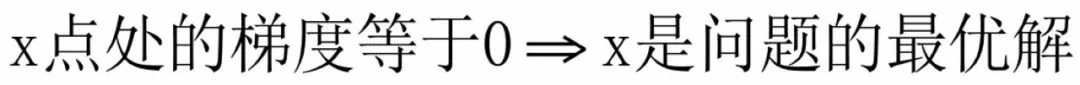
问题将会得到简化。如果对问题加以限定,是可以保证上面这个条件成立的。其中的一种限制方案是:
对于目标函数,我们限定是凸函数;对于优化变量的可行域(注意,还要包括目标函数定义域的约束),我们限定它是凸集。
同时满足这两个限制条件的最优化问题称为凸优化问题,这类问题有一个非常好性质,那就是局部最优解一定是全局最优解。接下来我们先介绍凸集和凸函数的概念。
凸集
对于n维空间中点的集合C,如果对集合中的任意两点x和y,以及实数0 ≤ θ ≤ 1,都有:
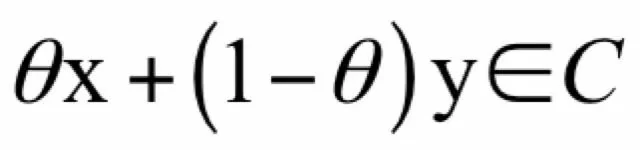
则称该集合称为凸集。如果把这个集合画出来,其边界是凸的,没有凹进去的地方。直观来看,把该集合中的任意两点用直线连起来,直线上的点都属于该集合。相应的,点:
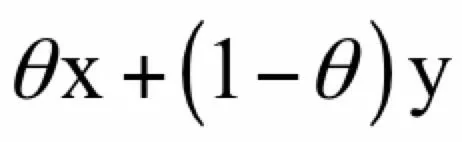
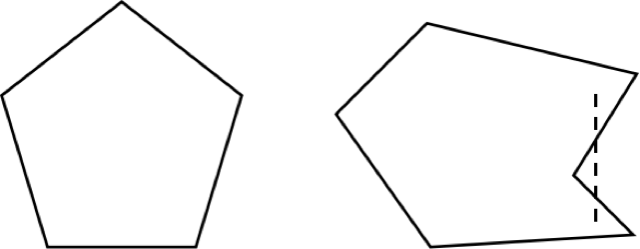
称为点x和y的凸组合。下图是凸集和非凸集的示意图,左边是一个凸集,右边是一个非凸集:
下面是实际问题中一些常见的凸集例子,记住它们对理解后面的算法非常有帮助:
n维实向量空间Rn。显然如果x,y∈Rn,则有:
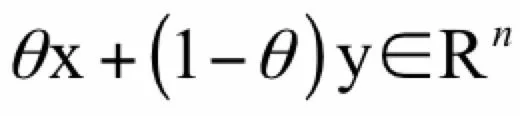
这一结论的意义在于,如果一个优化问题是不带约束的优化,则其优化变量的可行域是一个凸集。
仿射子空间。给定m行n列的矩阵A和m维向量b,仿射子空间定义为如下向量的集合:
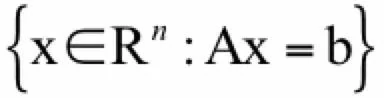
回忆一下线性代数中所学的,它就是非齐次线性方程组的解。下面我们给出证明。假设x,y∈Rn并且:
对于任意 0 ≤ θ ≤ 1,有:
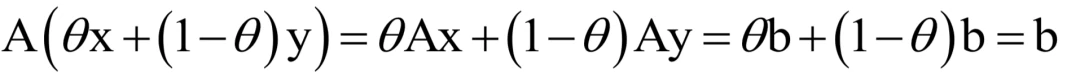
这一结论的意义在于,如果一组约束是线性等式约束,则它确定的可行域是一个凸集。
多面体。多面体定义为如下向量的集合:
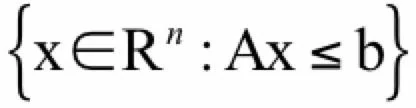
它就是线性不等式围成的区域。下面我们给出证明。对于任意的x,y∈Rn,并且Ax≤b,Ay≤b,如果 0 ≤ θ ≤ 1,则有:
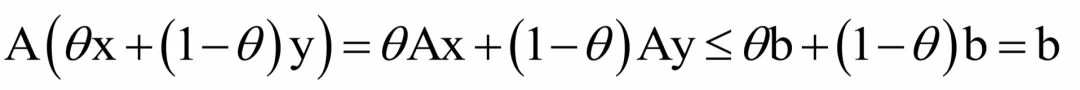
这一结论的意义在于,如果一组约束是线性不等式约束,则它定义的可行域是凸集。在实际应用中,我们遇到的等式和不等式约束一般是线性的,因此非常幸运,它们定义的可行域是凸集。
一个重要的结论是:多个凸集的交集还是凸集。这个结论的实际价值是如果每个等式或者不等式约束条件定义的集合都是凸集,那么这些条件联合起来定义的集合还是凸集,而我们遇到的优化问题中,可能有多个等式和不等式约束,只要每个约束条件定义的可行域是凸集,则同时满足这下约束条件的可行域还是凸集。需要注意的是,凸集的并集并不是凸集。
凸函数
在微积分中我们学习过凸函数的定义,下面来回忆一下。在函数的定义域内,如果对于任意的x和y,以及实数 0 ≤ θ ≤ 1,都满足如下条件:
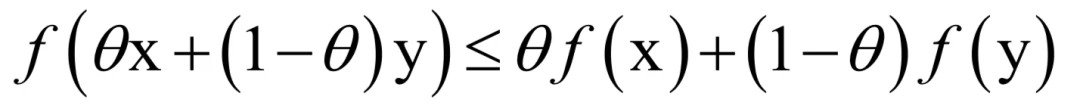
则函数为凸函数。这个不等式和凸集的定义类似。从图像上看,一个函数如果是凸函数,那么它是向下凸出去的。用直线连接函数上的任何两点A和B,线段AB上的点都在函数的上方,如下图所示:
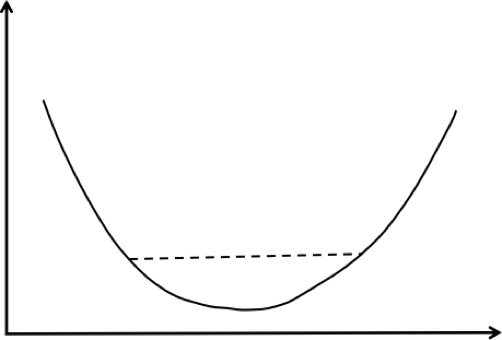
如果把上面不等式中的等号去掉,即:
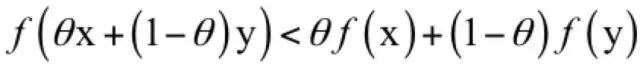
则称函数是严格凸函数。凸函数的一阶判定规则为:
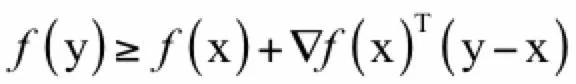
其几何解释为函数在任何点处的切线都位于函数的下方。对于一元函数,凸函数的判定规则为其二阶导数大于等于0,即:
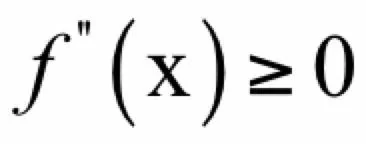
如果去掉上面的等号,则函数是严格凸的。对于多元函数,如果它是凸函数,则其Hessian矩阵为半正定矩阵。如果Hessian矩阵是正定的,则函数是严格凸函数。
Hessian矩阵是由多元函数的二阶偏导数组成的矩阵。如果函数二阶可导,Hessian矩阵定义为:
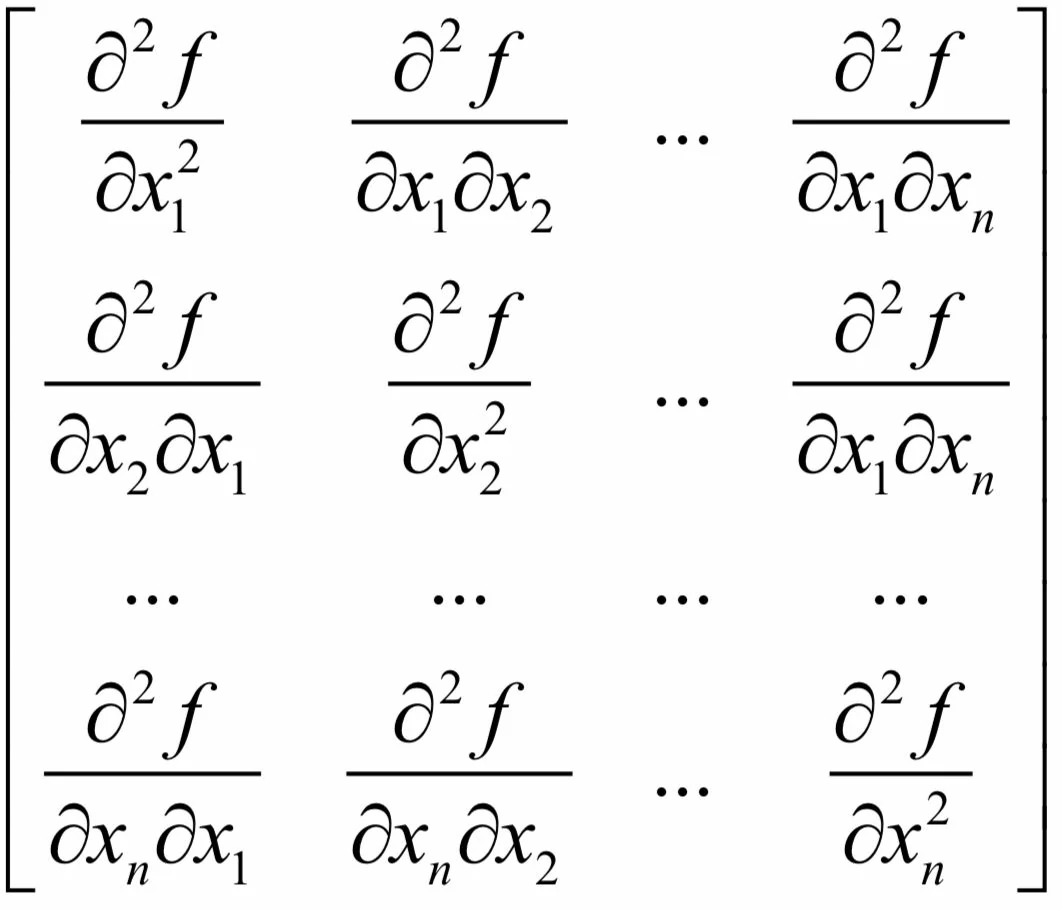
这是一个n阶矩阵。一般情况下,多元函数的混合二阶偏导数与求导次序无关,即:
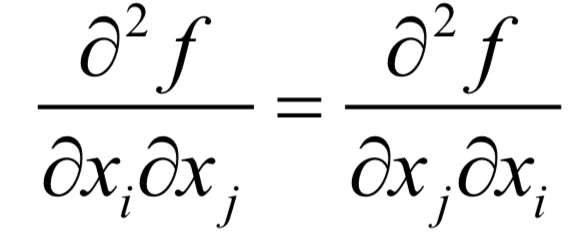
因此Hessian矩阵是一个对称矩阵,它可以看作二阶导数对多元函数的推广。Hessian矩阵简写为∇2 f (x)。对于如下多元函数:
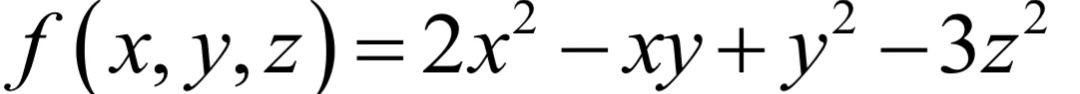
它的Hessian矩阵为:
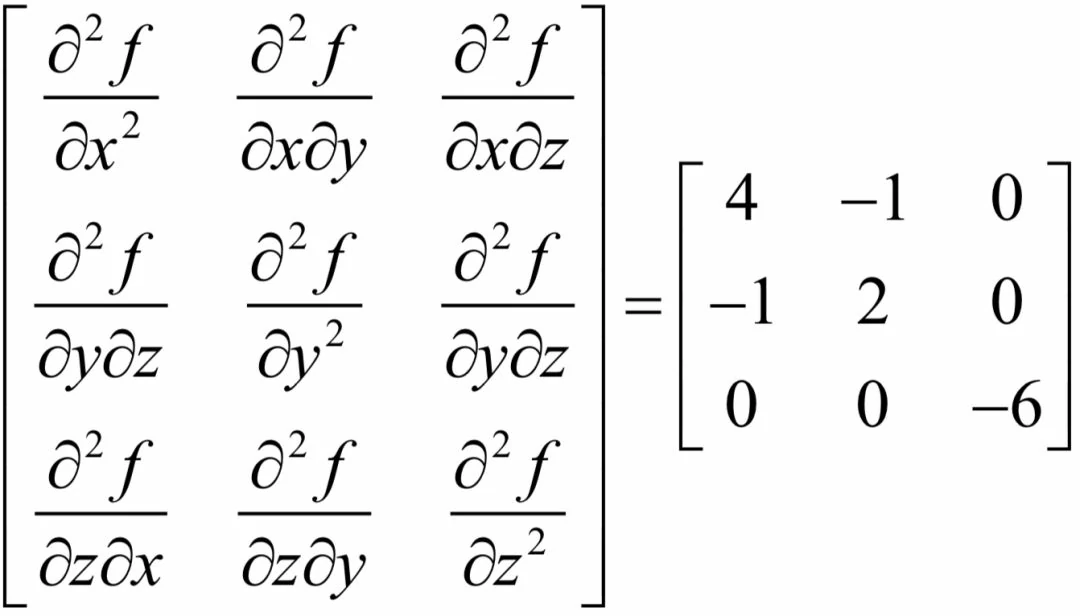
根据多元函数极值判别法,假设多元函数在点M的梯度为0,即M是函数的驻点,则有:
- 如果Hessian矩阵正定,函数在该点有极小值
- 如果Hessian矩阵负定,函数在该点有极大值
- 如果Hessian矩阵不定,还需要看更高阶的导数
这可以看做是一元函数极值判别法对多元函数对推广,Hessian矩阵正定类似于二阶导数大于0,其他的以此类推。对于n阶矩阵A,对于任意非0的n维向量x都有:
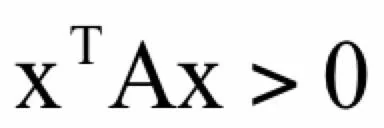
则称矩阵A为正定矩阵。判定矩阵正定的常用方法有以下几种:
- 矩阵的特征值全大于0。
- 矩阵的所有顺序主子式都大于0。
- 矩阵合同于单位阵I。
类似的,如果一个n阶矩阵A,对于任何非0的n维向量x,都有:
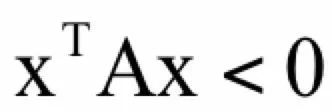
则称矩阵A为负定矩阵。如果满足:
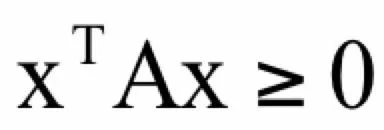
则称矩阵A为半正定矩阵。
一个重要结论是凸函数的非负线性组合是凸函数,假设fi是凸函数,并且wi ≥0,则:
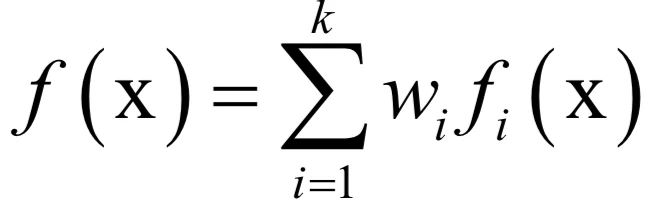
是凸函数。可以根据凸函数的定义进行证明。
下水平集
给定一个凸函数以及一个实数α,函数的α下水平集(sub-level set)定义为函数值小于等于α的点构成的集合:
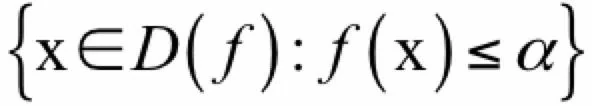
根据凸函数的定义,很容易证明该集合是一个凸集。这个概念的用途在于我们需要确保优化问题中一些不等式约束条件定义的可行域是凸集,如果是凸函数构成的不等式,则是凸集。
凸优化
有了凸集和凸函数的定义之后,我们就可以给出凸优化的定义。如果一个最优化问题的可行域是凸集,并且目标函数是凸函数,则该问题为凸优化问题。凸优化问题可以形式化的写成:
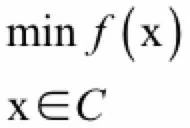
其中x为优化变量;f为凸目标函数;C是优化变量的可行域,是一个凸集。这个定义给了我们证明一个问题是凸优化问题的思路,即证明目标函数是凸函数(一般是证明它的Hessian矩阵半正定),可行域是凸集。凸优化问题的另一种通用写法是:
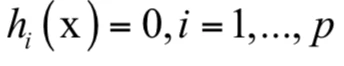
其中是gi (x)不等式约束函数,为凸函数;hi (x)是等式约束函数,为仿射函数。上面的定义中不等式的方向非常重要,因为一个凸函数的0-下水平集是凸集。因此这些不等式共同定义的可行域是一些凸集的交集,仍然为凸集。通过将不等式两边同时乘以-1,可以保证把不等式写成小于号的形式。前面已经证明仿射空间是凸集,因此加上这些等式约束后可行域还是凸集。
局部最优解与全局最优解
对于一个可行点x,如果在其邻域内没有其他点的函数值比该点小,则称该点为局部最优,下面给出这个概念的严格定义:对于一个可行点,如果存在一个大于0的实数δ,对于所有满足:
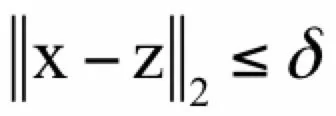
即x的δ邻域内的点z,都有:
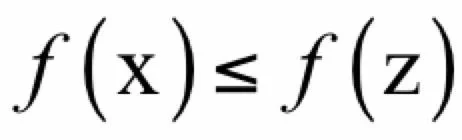
则称x为局部最优点。对于一个可行点x,如果可行域内所有点z处的函数值都比在这点处大,即:
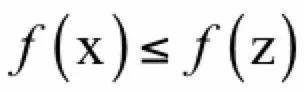
则称x为全局最优点,全局最优解可能不止一个。凸优化问题有一个重要的特性:所有局部最优解都是全局最优解。这个特性可以保证我们在求解时不会陷入局部最优解,即如果找到了问题的一个局部最优解,则它一定也是全局最优解,这极大的简化了问题的求解。下面证明上面的结论,采用反证法,具体证明如下:
假设x是一个局部最优解但不是全局最优解,即存在一个可行解y,有:
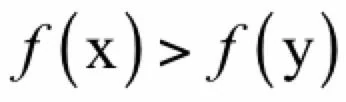
根据局部最优解的定义,不存在满足:
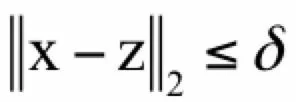
并且
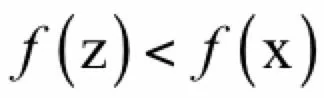
的点。选择一个点:
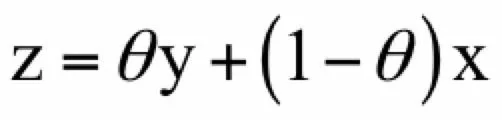
其中:
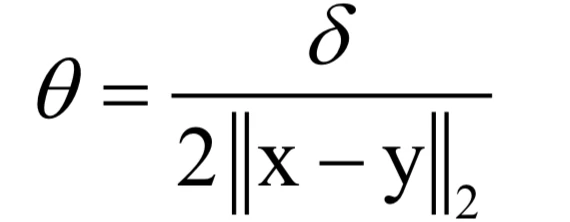
则有:
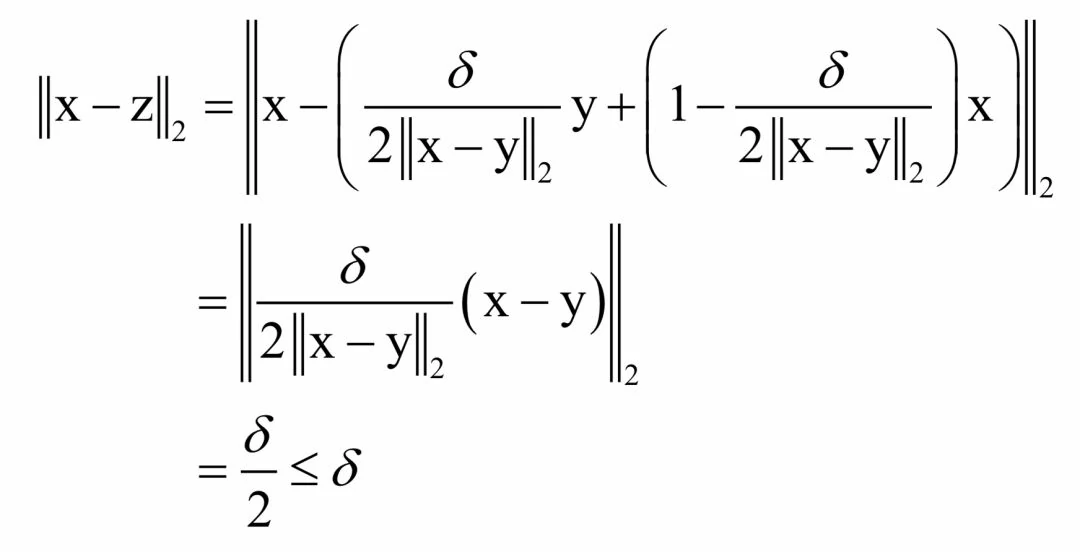
即该点在x的δ邻域内。另外:
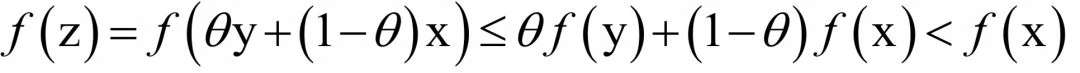
这与x是局部最优解矛盾。如果一个局部最优解不是全局最优解,在它的任何邻域内还可以找到函数值比该点更小的点,这与该点是局部最优解矛盾。
之所以凸优化问题的定义要求目标函数是凸函数而且优化变量的可行域是凸集,是因为缺其中任何一个条件都不能保证局部最优解是全局最优解。下面来看两个反例。
情况1:可行域是凸集,函数不是凸函数。这样的例子如下图所示:
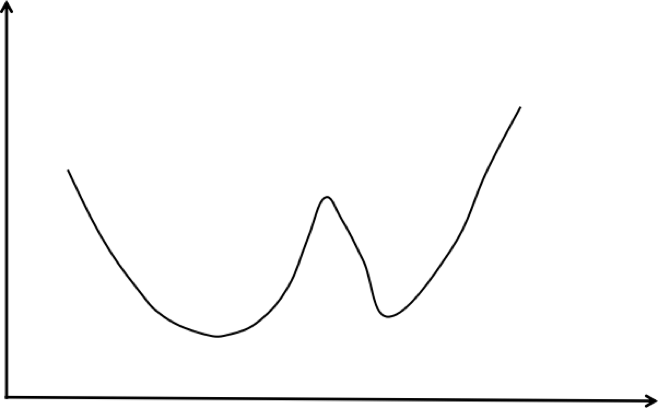
上图中优化变量的可行域是整个实数集,显然是凸集,目标函数不是凸函数,有两个局部最小值,这不能保证局部最小值就是全局最小值。
情况2:可行域不是凸集,函数是凸函数。这样的例子如下图所示:
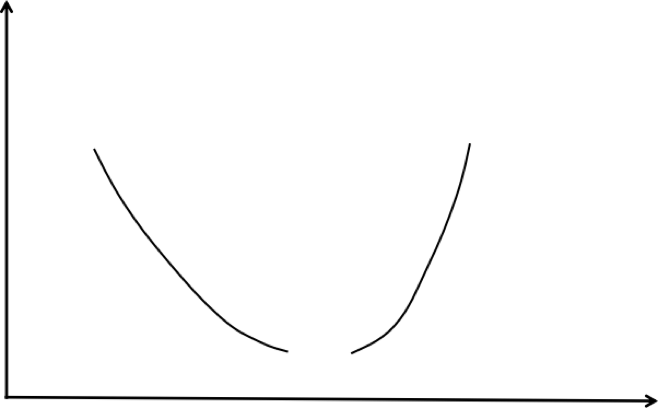
在上图中可行域不是凸集,中间有断裂,目标函数还是凸函数。在曲线的左边和右边各有一个最小值,不能保证局部最小值就是全局最小值。可以很容易把这个例子推广到3维空间里的2元函数(曲面)。由于凸优化的的目标函数是凸函数,Hessian矩阵半正定,因此不会出现鞍点,所以找到的梯度为0的点一定是极值点。
求解算法
对于凸优化问题,可以使用的求解算法很多,包括最常用的梯度下降法,牛顿法,拟牛顿法等,它们都能保证收敛到全局极小值点。梯度下降法在之前的文章中已经介绍,牛顿法和拟牛顿法在接下来的文章会介绍。
机器学习中的凸优化问题
下面我们来列举一下机器学习中典型的凸优化问题。
线性回归
线性回归是最简单的有监督学习算法,它拟合的目标函数是一个线性函数。假设有l个训练样本(xi , yi),其中xi为特征向量,yi为实数标签值。线性回归的预测函数定义为:
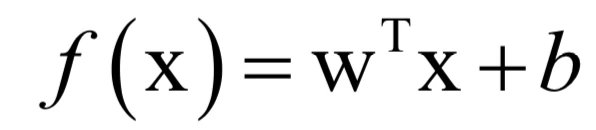
其中权重向量w和偏置项b是训练要确定的参数。定义损失函数为误差平方和的均值:
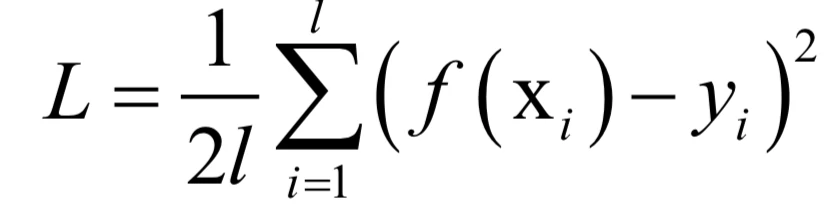
将回归函数代入,可以得到如下的损失函数:
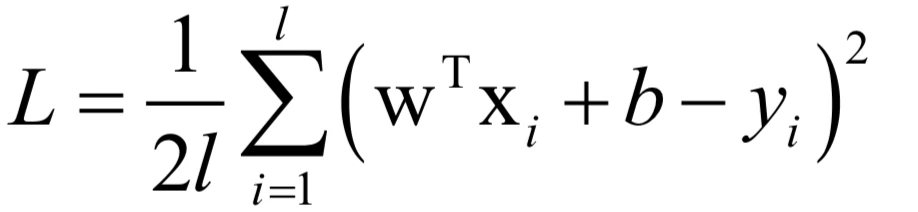
如果将权重向量和特征向量进行增广,即将w和b进行合并:
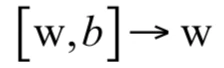
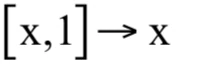
目标函数可以简化为:
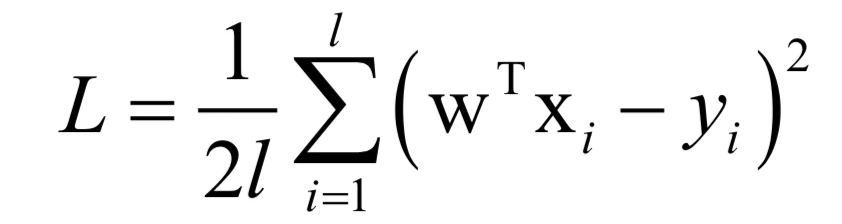
可以证明这个目标函数是凸函数。目标函数展开之后为:
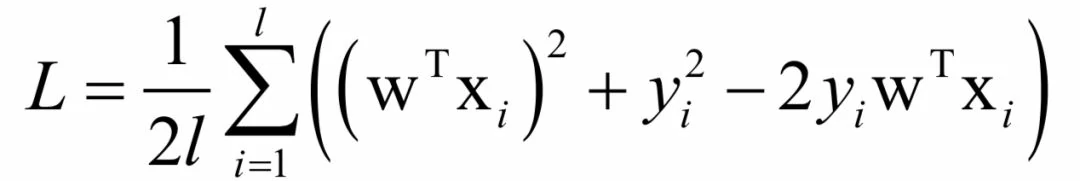
它的二阶偏导数为:
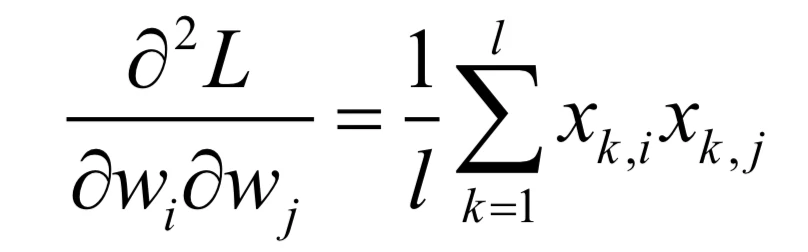
因此它的Hessian矩阵为:
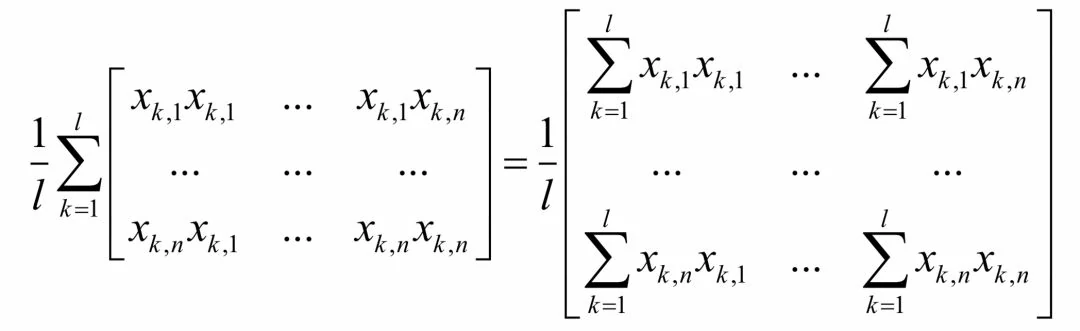
写成矩阵形式为:
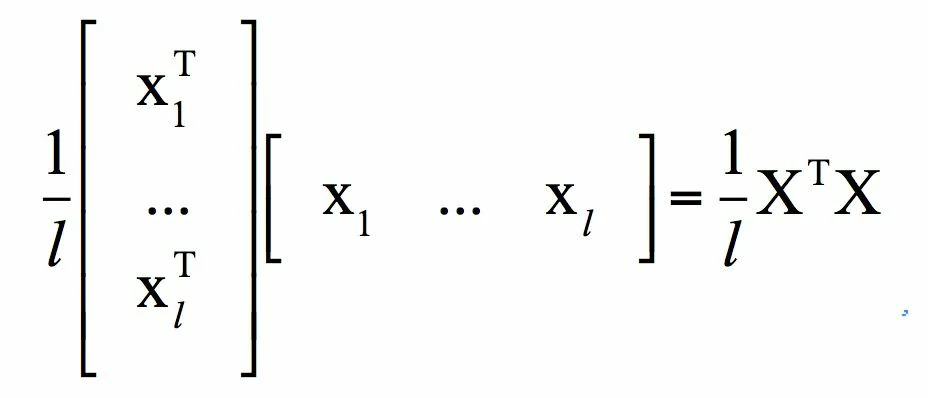
其中X是所有样本的特征向量按照列构成的矩阵。对于任意不为0的向量x,有:
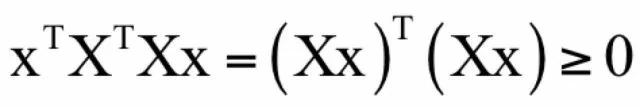
因此Hessian矩阵是半正定矩阵,上面的优化问题是一个不带约束条件的凸优化问题。可以用梯度下降法或牛顿法求解。
岭回归
岭回归是加上正则化项之后的线性回归。加上L2正则化之后,训练时优化的问题变为:
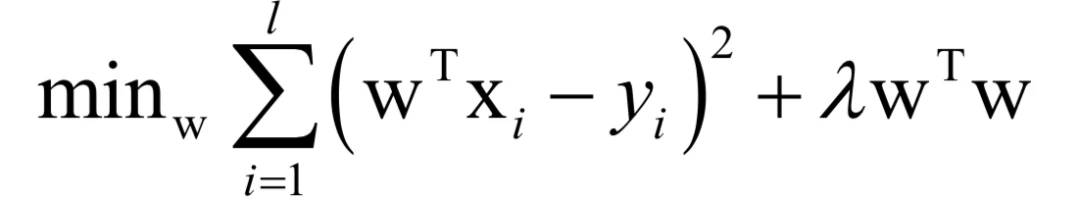
同样的,我们可以证明这个函数的Hessian矩阵半正定,事实上,如果正则化项的系数大于0,它是严格正定的。限于篇幅,我们在这里不给出详细证明。
支持向量机
之后会有一篇名为“通过一张图理解SVM的脉络”的文章介绍了支持向量机的推导过程,如果读者对支持向量机没有基本的概念,请先阅读那篇文章。支持向量机训练时求解的原问题为:
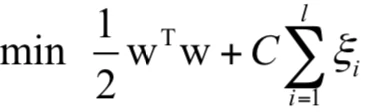
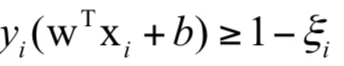
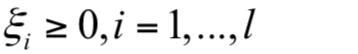
显然,这些不等式约束都是线性的,因此定义的可行域是凸集,另外我们可以证明目标函数是凸函数,因此这是一个凸优化问题。
通过拉格朗日对偶,我们转换为对偶问题,加上核函数后的对偶问题为:
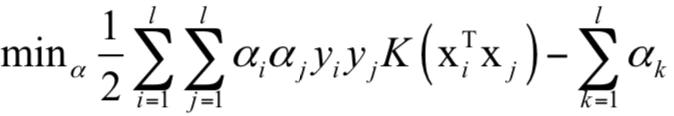


这里的等式约束和不等式约束都是线性的,因此可行域是凸集。根据核函数的性质,我们可以证明目标函数是凸函数。
logistic回归
logistic回归也是一种常用的有监督学习算法。加上L2正则化项之后,训练时求解的问题为:
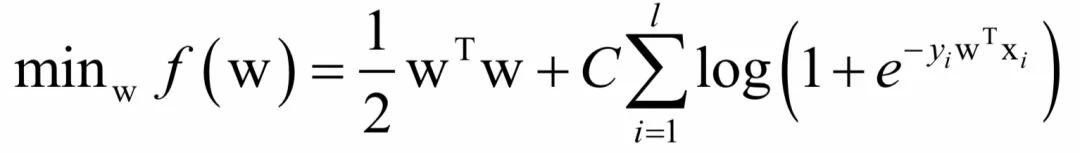
这是一个不带约束的优化问题,我们可以证明这个函数的Hessian矩阵半正定。
softamx回归
softamx回归是logistic回归对多分类问题的推广。它在训练时求解的问题为:
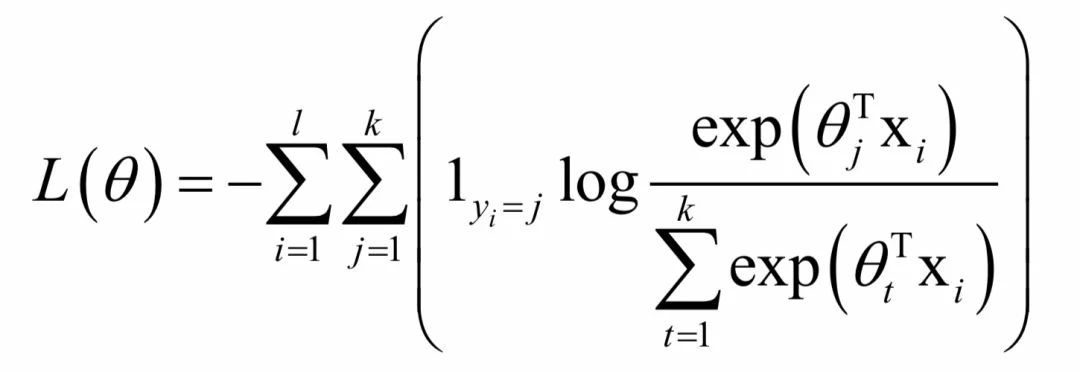
这是一个不带约束的优化问题,同样的可以证明这个目标函数是凸函数。除此之外,机器学习中还有很多问题是凸优化问题,限于篇幅不能一一列出。由于是凸优化问题,这些算法是能保证找到全局最优解的。而神经网络训练时优化的目标函数不是凸函数,因此有陷入局部极小值和鞍点的风险,这是之前长期被人诟病的。