
导读
我们看这个世界主要有两种方式:一种方式是从上往下看世界;另外一种是东方人所擅长的《易经》方法看世界,也就是归纳法,从下往上看世界。《易经》追求三易,不易、变易和简易。大道至简,《易经》的这三易如何指导我们做数据挖掘以及人工智能研究呢?(本文按熊辉教授于第三次人工智能前沿讲习班上的报告
作者简介
熊辉教授本科于1995年毕业于中国科学技术大学,博士于2005年毕业于美国明尼苏达大学,目前为美国罗格斯-新泽西州立大学信息安全中心主任、罗格斯商学院管理科学与信息系统系副系主任、正教授 (终身教授)、RBS院长讲席教授,并担任中国科学技术大学大师讲席教授。熊辉教授在研究领域成绩斐然,获得的部分荣耀包括ACM杰出科学家,长江讲座教授,海外杰青B类(海外及港澳学者合作研究基金), IBM 创新奖, ICDM-2011最佳研究论文奖,罗格斯-新泽西州立大学最高学术奖—the Rutgers University Board of Trustees Research Fellowship for Scholarly Excellence (2009)。 主要学术成果包括:1本专著;3本编著,其中Encyclopedia of GIS(Springer)被评为最受欢迎前十名的Springer华人作者的计算机著作; 学术论文200余篇,其中有60余篇发表在包括 IEEE Transactions on Knowledge and Data Engineering、VLDB Journal、IEEE Transactions on Fuzzy Systems、Machine Learning、IEEE Transactions on Systems, Man, and Cybernetics - Part B、IEEE Transactions on Mobile Computing在内的顶级权威刊物上,有32篇发表在数据挖掘的顶级学术会议 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD)上。
我选择从事数据挖掘行业的三大原则
我为什么选择数据挖掘这个行业呢?我读过很多科技杂志,也读了很多人文学科书籍,特别是中国的国学,算是熟读了《孙子兵法》、《易经》和《鬼谷子》,这都是我最喜欢的书。熟读之后,我考虑一个问题:将来应该选择什么样的方向?当时我给自己职业发展定了三个原则:第一个是兴趣原则,必须是自己感兴趣的事情;第二是朝阳原则,这个行业要随着时间发展往上走,是一个朝阳行业;第三是复合原则,要有足够的复杂性。大概是1996年,我碰巧看到了数据挖掘的介绍,那时候很早,KDD还是一个Workshop(音)的时候,相当于数据挖掘刚刚出来的时候。我看了这个方向挺好,符合我的三个原则。
原则一:兴趣原则
我这个人从小对历史感兴趣,虽然是理工男。历史是什么?历史是读过去、知未来,本身就是一个预测问题。我对数据挖掘感兴趣是自己天然的本性而已。
原则二:朝阳原则
为什么说数据挖掘是一个朝阳性行业?1996年、1997年互联网出来,1999年到顶峰,2000年泡沫破裂。互联网真正带来的改变,一大改变就是数据,把世界上的人都连在一起了,当人以指数的方式联系在一起产生的就是数据。现在是物联网,所谓互联网的第二代,物联网把每个设备连在网络,现在每个人平均4个设备,这个连在一起会有多少数据?从某种意义上,我最喜欢用医生做对比,我们做数据挖掘行业最像医生。大家都看过病,一个病人见医生的时候,医生首先问你哪里不舒服,你的病症是什么,可能依赖一些询问方式,可能依赖一些医疗设备诊断的方式,可以提取出来很多特征。我们的病人是数据,可能从通讯领域、医药领域、金融领域、市场领域来,也可能从企业管理中来。这些数据来了之后,我们首先提取的是特征,看看这些数据具备什么样的特征,这些特征可以帮助我们下一步选择合适的模型。比如说这个数据有高危性、稀疏性,具有不同的统计学特征等。这两个很相似,医生需要了解病症,我们需要了解数据特征,对我们而言,我们的病人就是数据而已。这两个行业是相通的,做好医生需要用好各种各样的工具,我们做好数据挖掘需要理解好各种各样的算法,也是异曲同工的,所以这两个行业是非常相似的。
原则三:复杂性原则
为什么要有足够的复杂性?随着科学技术的发展,很多工作会慢慢被机器淘汰,如果这个行业不够复杂、不够与人交互,这个行业就会被淘汰,所以我从事的行业必须是一个复杂行业。只有复杂行业才能维持朝阳。至少在我有生之年。医生非常难被机器淘汰,现在机器已经超越人下围棋了,但是机器很难替代人去看病。机器可以做标准化、逻辑化的事情,医生可以做什么事情?同一种病毒所感染的流行感冒,这个是怀孕的妇女,那个是有心脏病的老人,这是一个小孩,那是一个青壮年,不同的病人被同一种病毒感染,医生的治疗方式必须是不一样的,怀孕妇女有一些药不能吃,有的心脏病患者有一些药也不能吃。这就是复杂性,个体差异性导致标准化过程非常困难。从这种角度来说,医生这个行业有足够的复杂性和足够的朝阳性,只要有人活着就需要有医生,所以我们这个行业跟医生非常像。我们既有朝阳性,因为病人越来越多,互联网第二代,随着物联网的产生,我们数据越来越多,代表病人越来越多,病人越来越多,我们的市场就越来越大。所以我们是朝阳性的行业,我们这个行业也非常复杂。
算命先生也做大数据?
我们这个行业还像一个行业,我一直喜欢研究这个东西,很早就喜欢看这个东西,如果我穿越到古代,在街头多半是一个算命先生,当然也有可能进入朝堂变成国师。但是我自己个人最喜欢鬼谷子,所以多半喜欢闲云野鹤,宁愿培养学生打仗,自己做好老师就可以了。
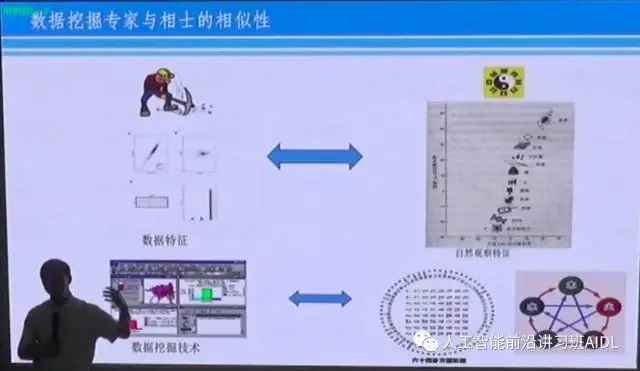
为什么说这个行业也特别像呢?我们不要把古代的相士简单看成迷信,其实他们也在做大数据,是一种垂直的大数据。什么是垂直的大数据?他们不具备我们的条件,比如说我们看手相,可以收集100万个人的手相,包括收集职业生涯链,根据手相和职业生涯寻找特征,然后再研究他的特征,可以用科学的方式研究这个问题。但是古代不可以,古代是一种垂直的,古代的人也会掌握很多知识,这个知识叫Knowledge Graph,但是这是脑袋里固化的一种知识,比如说日月星辰的变化、四季的变化、各种事物之间相生相克的关系,包括动物的食物链和各种知识。他们还掌握一些基本的工具,比如说金木水火土五行的理论和算卦的理论,这东西是他们掌握的非常原始的、非常朴素的,你可以说是非科学化的知识结构和工具。所以,他们跟我们也是很像的。
为什么我跑去学《易经》呢?
做数据挖掘越做到最后,发现当年在深圳看的《易经》有用,因为这可以指导我很多的思维方式和哲学思想,包括我的很多算法设计都是从《易经》思想中来的。《易经》很简单,《易经》追求的是什么?《易经》追求的三易,不易、变易和简易。我们做很多模型的设计,我们预测模型,首先考虑的是不易,因为建立模型的时候只能把握不容易随着时间改变东西,你需要把握事物之间最根本、最本质,不容易随着时间、地点改变的东西,这就是《易经》“不易”的精神。易学本身就是对大自然观察总结的一些结果。

这里做一个例子,比如我刚才说算命是一种垂直大数据,比如说手相,当然这不是我今天讲课的重点,我只是用这个来阐述相关性。我说算命是一种垂直大数据。什么叫垂直大数据呢?比如说手相,现在已经证明是可以被科学化的。乔斯科普克斯在两年前发表了一篇《Nature》的文章,人的经历可以在手上留下痕迹,你生过大病在手上会留下痕迹,你经历过感情挫折手上也会留下痕迹,因为会改变你的腺体的分布,因为腺体分布的改变会导致手上痕迹的改变,这是有科学依据的。但是古代人不知道这些事情,古代人只能做到垂直大数据,什么叫垂直大数据?比如说一个非常聪明的人,可能是伏羲或者周文王,周文王看了手底下很多大臣、士兵的手相,他可能一辈子看了十万人手相,发现中间有事业线的人事业发展的很好,就把这条线叫事业线,事业线长得又直又深的人这些人会发展比较好。他观察了很多事物,总结出来一个规律而已。他把这个传给他的徒弟,这个徒弟又看了另外一条感情线,徒弟的徒弟可能又看了一条生命线,这个垂直线下来可能看了几百万人的数据,最后总结出来几个规律而已。每一条数据线对于我们做数据挖掘的就是feature,仅此而已。这种是靠垂直观察产生的模式,但是我们现在可以做水平的观察,可以一次性收集很多数据来做这个事情。

我们看这个世界主要有两种方式,一种方式是从上往下看世界,另外一种方式是东方人所擅长的《易经》的方法,也就是归纳法,从下往上看世界,这是我们做数据挖掘的人非常擅长的。因为我们东方人太能够从下往上做归纳法了,以至于我们很难产生逻辑化的体系。只要大家从这个就可以看出来,东西方两种思维方式区别是很大的,我们东方人一直说从底下往上看世界,从归纳法看世界,中国就拍得出《琅琊榜》,美国不会拍《琅琊榜》。在没有计算机的时代,《琅琊榜》的数据收集方法已经达到顶峰了,包括数据的整理方法和数据的收集方法。
个人的观点,之所以中国在近代会落后,那是因为中国方法论的落后。18世纪开始中国为什么会落后?原因非常简单,中国人的思维方式是从下往上看世界。从下往上看世界依赖两个条件,第一要数据好,覆盖率高,精细。第二个条件是数据分析能力强,近代社会我们没有计算机,数据分析能力不强,《琅琊榜》的数据方法是我们数据收集能达到的顶峰了。某种程度而言,过去几千年我们数据收集方法和数据处理能力都没有重大的改变;现代社会中,当计算机出来之后我们才出现重大改变。近代的时候,西方数学逻辑体系得到极大完善,西方工业体系得到极大完善,这就产生巨大冲击,就使近代社会西方会超越我们东方。
现在我们的机会是大数据,我们从来没有像现在这么好的机会,可以掌握这么细致的数据,从来没有么好的机会可以深入毛孔的看人和人之间的关系,所以现在无论从数据质量和数据收集方法都是前所未有的好,我个人认为未来社会的人才应该是中西贯通的,既懂得西方的逻辑思维数学体系,还包括东方式的大数据分析能力,将来这会帮助到大家。
我刚才说过了,整个人类发展的过程是一个拔河的过程。人的智能和人工智能,我们人创造出来很多人工智能,帮助我们去做什么事情?帮助把很多以前属于人类的工作都归于机器了。什么样的工作会归于机器?逻辑化、标准化的工作会被机器所替代,替代过程最近十几年会加快,未来十几年会加得更快,等一下会跟大家讲我的理念,我为什么做人的研究?等一下就会解释。因为这个过程中会导致很多人失业,导致很多人知识结构不再有用,对人的挑战非常大。

人工智能替换了什么?替换了人的计算能力,替换了人的存储能力,很多以前属于人类的工作现在都是机器在做。未来发展的三大特征:一个是快,一个是准,一个是狠。这是什么意思呢?我们现在整个社会的发展,过去十年的发展比整个人类历史发展的总和还快,非常非常快。这个快会导致什么结果?一个企业的变化、一个组织的变化、一个国家的变化,包括个人的变化,过去一个企业从0到1000亿美元需要花几十年积累甚至上百年积累,现在一个企业从0到10亿美元可能几个月就够了。反之,一个企业从上千亿美元到破产几个月也就够了,所以现在一切都在加快。现在我们对未来的很多判断会变得更加精准,这个精准是因为现在的大数据和我们的分析能力。还有一个“狠”,现在任何一个行业,以前我们有传统的食物链,鲨鱼吃大鱼,大鱼吃中鱼,中鱼吃小鱼,小鱼吃虾米,现在鲨鱼把所有东西都吃掉,所以这是一个非常狠的时代,这个时代中一定要提升自己的竞争力。
为什么要“研究人”?高颜值以后将不会成为面试优势!
我从05年开始去商学院,去商学院最大的原因是我认为在商业领域拥有最多的数据。从05年我博士毕业开始到现在,我们是做移动推荐的,我从05年、06年就开始做出租车的GPStrees(音),那时候中国没有滴滴,美国也没有Uber,我们06年和旧金山的出租车厂商合作去分析他们出租车的GPStrees,所以我们发文章很早,06年、07年我们开始发GPStrees的文章,全世界没有几个人拥有那个数据。然后开始做基于人的行为分析,还做过很多金融的商业数据,还做过客户的数据分析。这些都做完之后,我突然意识到一个问题,不管我做数据是从移动领域来、从通讯领域来还是从金融领域来、市场领域来,都离不开一个本质,最终都回到“人”本身了。
人是最难研究的,把人研究透了就没有什么东西不懂了。任何组织、任何国家离不开两个东西,一个是对人的研究,一个是对金融的研究,一个管住人,一个管住钱。现在我来进行对人的研究。两年多前我开始做这个研究。传统上大家对企业的人的研究是什么研究方式?我发现传统上很多是经验型的。什么叫做经验型的?企业要提谁做一个总监、提谁做一个VP很多是拍脑袋做的决定。什么叫做拍脑袋做的决定?为什么提他?我只是感觉他好。好在什么地方?他不能回答这样的问题。什么叫做科学,假设我提拔一个人做总监,我要知道这个总监的职责是什么,他的主要职责包括一二三四五方面,这个人技能也有一二三四五,包括他的个性是不是符合这个岗位的需求,这是科学化的工作匹配、岗位匹配。用《易经》的说法我们叫做“当位”。我们判断一个人是不是可以处于一个职位,要判断他个人的技能、个人的情商和个人的条件是不是符合这个岗位的需求。这就是科学化的评估。
过去很多是主观的,现在尽量要客观。什么是主观,什么是客观?很简单,大家大学毕业去面试,如果你长得漂亮,现在还有优势,再过几年就没有优势了。之所以有优势,因为你到腾讯、阿里、百度面试,你长得漂亮,面试程序员,面试的程序员看你长得漂亮第一关就很容易过。所以管理的人说,这个人怎么直接到我这一关的,前面的工程师怎么面试的,怎么一下到经理这一关面试了,这是非常主观的。现在我在开发一种面试机器人,首先是机器面的,所以不用担心这个问题。这个应用会很快,不只是我开发。现在是机器把关,机器自动筛选你的简历,机器做面试机器人,会跟你对话,给你提面试问题,会自动评估你的面试答案。
现在很多判断是碎片化的。什么叫碎片化?我们对信息收集的渠道和完整性不如以前,现在要基于完整信息判断。以前很多判断是模糊化的,以前很多判断是滞后的,现在要做前瞻。什么叫前瞻?我们设计的一个非常好的算法是离职预测,我们现在判断离职非常准,我们可以非常准确的判断出谁在未来几个月离职。为什么我要判断人家要离职?举个例子,假设这个人处于这个公司独一无二的角色,我判断他要离职,如果没有替代的,我是不是要做挽留,提前去干预。如果干预不了、挽留不了,可能要到市场上招一个这样的人,或者从企业内部挖掘一个可以替代他的人,这就叫前瞻,灾难没有发生之前就开始处理掉,这就像扁鹊说他哥哥的能力比他强,因为人家可以提前知道这个小病会发展到大病,所以我们要从滞后性往前瞻性转移。
易经的“不易”
我研究整个人才智库的开发,你说这个怎么切入?两年多前我对人力资源一窃不通,我两年之前没有做过企业人力资源管理,原来在深圳带过一个小团队,有一点点认识。我需要考虑什么呢?现在我需要考虑整个人力资源管理应该怎么去切入,就像我刚才跟大家说过,我做过市场分析、做过金融,我现在又做人力资源管理,大家肯定觉得很好奇,你怎么可以懂那么多领域知识,这就是学《易经》的好处了。我们学《易经》的人学习有方法的,学习任何领域,我只学习不易的东西。什么叫做不易的东西?“易”有三易,不易、变易、简易。

不易是什么?任何一个行业、任何一个事物都会有不变的根本,不会随着时间、地点和你面对的场景而轻易发生改变的事情,这就叫不易。学习任何行业,首先要学习的就是不易。做人力资源有什么不易?大家听完这个就知道什么叫做人力资源,人力资源从古至今都有,从盘古开天形成组织就需要人力资源,战国时期各个国家,秦楚燕韩赵魏都需要。秦朝做组织管理也需要做人的层面的管理、组织层面的管理、文化层面的管理。现代社会,无论美国、中国还是各个企业,同样,你的管理无非是三个层面:对人的管理、对组织的管理、对文化的管理。对人的管理包括什么?无论一个小公司、大公司,过去的国家、现在的国家,过去的企业、现在的企业都离不开“录、离、升、降、调、选、用、育、留、辞”十个字,不管你用什么技术,离不开这些东西。首先,你录什么人、选什么人、用什么人、培养什么人、你让谁滚蛋、你保留谁,这些事情是不变的,跟你的工具没有关系,跟你的企业类型没有关系,跟你生活在古代、现代没有关系,这就是《易经》“不易”的根本。
对于组织的管理,不管是红军长征时代还是现在中国政府面对的情况,首先是组织的领导力、组织的稳定性和组织的激励机制,这涉及到对组织的管理。对文化的管理涉及到什么?任何企业、任何组织、任何国家都离不开愿景。任何组织的文化体现在哪里?体现在这个组织的价值观,你的价值评估是什么、价值标准是什么、价值分配的原则是什么,包括公司的远景和公司的未来是什么,使命感在哪里。
易经的“变易”
但是,光知道不易还不够,任何事物都会变化,它有它的变易,但是变化不是乱变化的,变化是有方向的,而且变化是有原则的。所以,我们做预测还要知道变化的方向和原则。任何组织、任何国家都离不开对人的管理、对组织的管理、对文化的管理,但是不同类型的企业对这三个要求不一样。小企业主要加强的是对人的管理,所以一个小企业的好坏主要看他的头儿,看这个领导、老板好不好。中型企业主要看什么?中型企业主要看它的组织,组织的领导型、稳定性和激励机制做得好不好。大型企业、大型组织乃至国家,一定要看文化做得好不好,这个国家、这个组织、这个党派、这个大企业有没有好的愿景、有没有好的使命感、有没有好的价值观。从某种意义上,当年国民党输给共产党是输在文化上面,不是输在人上、也不是输在组织上,而是输在文化上。所以,学习这个东西一定要知道它的“变易”体现在哪里。
难点在哪里?我这辈子研究数据挖掘,从1999年到现在,我觉得最难研究的就是人,因为人的数据提取特征是最难的。现在回到这个根本的问题,过去做人的研究、组织的研究、文化的研究靠什么?古代靠人的大脑,现在我们要靠数据收集。现在我要回答的问题是我们怎么通过大数据分析的方法、通过数据收集的方法做到对人的管理、对组织的管理、对文化的管理,怎么通过抽象的向量化的方向做转移,这是真正的难点。
易经的“简易”
刚才介绍完了关于“不易”和“变易”。我们把握住不易、把握住变易,一定知道什么叫简易。简易是做数据挖掘要会的,你要学会做聚类。聚类是一种简易的办法,可以帮助我们理解、帮助我们去做总结。任何一个学科不易的东西和变易的方向,必须要掌握简易的方法,只有这样才可以快速学习。
很多学生不会学习,如果你整天学习的都是正在变化过程中的东西,你的学习就白学了。很多学生跟我说,“我在学习怎么做去网站”,我说过了十年以后你一无是处,你就白学了。两个学生,一个学生都在学习知识,这个知识的挥发性是很慢的,哪怕他每天只学三个小时;这个学生每天学九个小时,但是他学的是今天学了两年之后就没有用的知识,属于高挥发性知识,属于完全变易的知识,白学了。过十年之后,这个每天学三个小时的学生比每天学九个小时的学生厉害多了,因为他的知识沉淀了,而另外同学的知识出的比进的还快。所以,学什么、怎么学非常重要。
给大家讲一个小的例子,判断一个人有领导力,怎么可以量化?这真是一个大学问。举一个简单的例子,领导力是要有看远的能力,也有看宽的能力。看远是什么?他知道未来会发生什么事情。看宽是什么?他知道自己的现状。带团队的能力是懂得识人、有胸怀、能放手。这些东西都不重要,重要的是我随便提取出来一条,你能不能告诉我什么样的数据可以反映一个人具备这些素质?我说这个人懂识人,我不能简单说他懂识人,我要有证据和数据来支撑“他能够识人”。举个例子,这个老师曾经挑了十个学生,这十个学生最后统统都失败了,都混的很惨,你说这个老师会识人,我不相信。或者一个公司的总监过去带了100号人,这100号人有50个是经过他面试的,结果这50人在企业中的表现基本上都是最差,你说他会识人,我才不相信他会识人,他肯定不会识人。先不说用人的事情,首先就不会识人。
任何一个东西,怎么提取数据来反映这个事实?有一些人是很虚的,我说可以看远,就是判断这个人有没有视野,能够看到远方,你通过什么数据可以判断这个人能够看到远方?你可以看这个人职业生涯链。举个例子,如果这个人90年代末加入Google,在2006年、2007年加入Facebook,这个人是很有视野的,总是在对得时机做对的选择,哪怕只是一个小工程师,他也是很有视野的,他可以看得到未来。如果一个人总是反过来,90年代末从Google跳槽到雅虎,后来从雅虎跳槽到更差的地方,你说你有视野,这不是开玩笑吗?这个人肯定没有视野的。怎样通过量化的办法来判断一个人有视野,他能够做到这上面的每一条。说起来很容易,做起来好难,我想了很长时间,每一条可以提取什么样的特征。
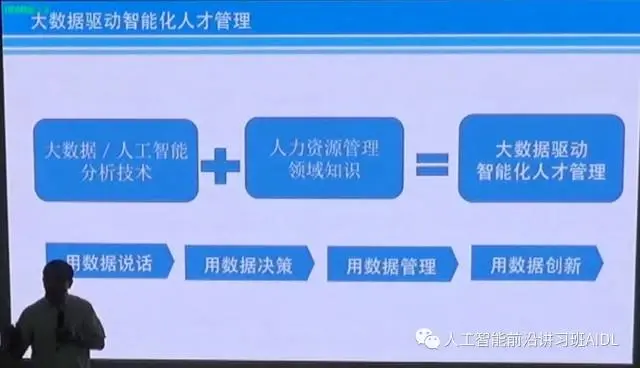
真正要想做好,我们需要两方面的技能:一方面是我们的专业技能,另外一方面要掌握这个领域知识。这个领域知识要掌握不易的领域知识,还要掌握变易的方向,这是真正要学习的。不管做金融数据分析、市场数据分析、安全数据分析还是沟通数据的分析,都离不开这个领域知识,真正的高手一定可以做到用数据说话、用数据决策、用数据管理。我自己觉得最难的,能够做到用数据创新的人很少,非常少的人可以做到用数据创新。我自己是一个非常注重学习的人,我强迫自己多学习一些领域知识,一定把自己的眼界打开。真正做很多预测模型,你就明白,一定要把握任何领域不易的东西,这个东西比你掌握算法难的多。
学习算法很容易,你可以简单的做一个规划,可以让自己学,今天把聚类学完,明天把分类的东西都学完,这个DeepLearning无非也就是把那几个算法学好,这些东西都简单,只要学得好。真正难的是把握难以把握的东西,看上去很多,我丢上去一个知识点,可能人力资源这么厚一本书,你说把这么厚一本书啃完不是件容易的事情,最难的是学生考完之后什么都没有学到,他不知道该读什么。你怎么样可以把一本厚书读薄,这是很难的事情。
让数据说话:面试官的评估与人才个性
给大家先介绍一下,我们怎么通过数据分析的方法来做一些事情。比如说我们做了很多很好玩的事情,面试官的评估与人才个性。我们首先考评一个公司谁是优秀的面试官,现在数据可以反映谁是优秀的面试官。比如说,你已经面试过50人,你要写面评,最后发现面试的50人中间有40个甚至45个都很差,你多半不合格。还有很多面试官就面试了10个人,这10个人都很好,进来之后是企业的顶尖人才,说明你的眼光非常好。数据是不会撒谎的。不只是这个,我们还看你写的面评,如果你的面评可以准确的反映到每一个候选人真正的实力的时候,包括他的优点和缺点你能够准确定位的话,我们就认为你是一个很好的面试官,我们建立一个模型来预测这件事情。第二个是我们做了很多智能广告的生成,根据一个企业不同的岗位我们会自动生成这种广告,这要用到邹老师介绍的东西。

介绍一个具体的例子。介绍的第一个事情是做人,比如说我们做智能简历的筛选和分发。我现在给大家描述两年之后、三年之后的中国现状。未来大家是校招的,很多学生将来会递简历,会填很多公司,很多公司会给你发一份招聘表,你把信息输入进去,这就是简历的收集过程。未来,所有企业都会收集所有的招聘信息。收集招聘信息之后干什么呢?电子化,电子化之后干什么?用自然语言处理去抽取你的技能,然后评估,评估你的专业技能、评估你的情商、评估你的沟通能力。仅仅用简历吗?当然不是,还会想办法去看你的社交网络,能够找到你任何信息,比如说你在微博上骂人的信息,那基本上是很糟糕的。
现在美国一个趋势是做背景调查,都是去你的Twitter和Facebook上看,如果你整天放一些色情暴力的东西,你就惨了,虽然过得了技术面,多半也拿不到工作,而且人家不会告诉你为什么,人家只是说,“根据我们的背景调查,你不符合我们公司的文化,对不起,不能录用你。”所以,大家在网上也要谨言慎行,千万不要以为自己蒙上脸之后别人就不知道你是谁了,千万不要乱说话。现在在美国做背景调查已经往这个方向发展,中国也很快,就两三年的事情。最可怕的是,一旦推上去你删都删不掉。你以为删得掉,有各种历史留痕的网站可以让你的历史展现出来。而且最关键的是很多公司想尽一切办法收集这样的数据,帮助把你从幕后带到台前,所以没有事不要乱骂人,behave yourself是最好的。
我们通过收集简历,通过收集所有的信息,可以找到每个人的能力,不只是你的专业技能,还包括了你自己的领导力、情商这些所有的东西,这涉及到很多自然语言处理的东西,包括简历的自动收集、整理这些情况。
第二个是什么呢?第二类数据就是JD,本身也是一个文档,中间会告诉你有岗位的需求和技能的需求。岗位的需求有对领导力的需求、对沟通能力的需求和对专业技能的需求,这个也可以量化。
有了这两类数据以后,我们做的是什么?我们做精准的简历分发。我公司有一个岗位,可以根据简历数据库做精准推荐,产生一个列表。我们还可以推荐几个合适的面试官,可以做到一体化操作。我们还可以让机器面试,机器给你提几个问题,也就是所谓的面试机器人,帮助你进入下一关。这是一个自动化的流程,这个自动化流程我们已经做好了,从最早的简历收集,简历收集完以后自然语言处理,然后再做岗位匹配,匹配完之后再推面试官,是整个环节的流程。我已经提前告诉大家两年后大家会面临的情况,很多大公司都会这样。这是所谓智能简历的定向和推荐。关于面试官还涉及到很多,这个方面不细讲了。
让数据说话:论人才的保留
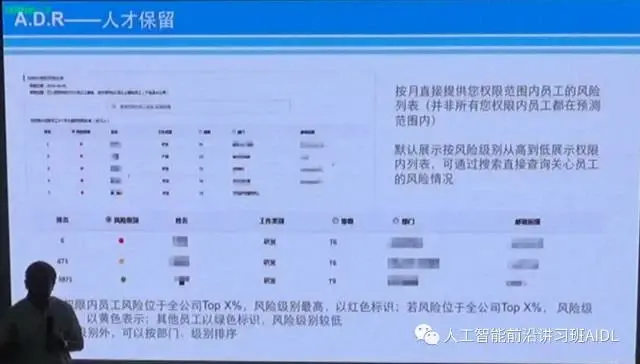
除了招聘和智能人才推荐之外,我们现在还做离职预测。现在离职预测非常精准,比如说在系统里你看到某一个人已经标红了,标红是什么意思?也就是未来三个月他离职的可能性非常大。作为领导,你要考虑的是什么?你想不想挽留他,如果你想挽留他要做什么动作,如果你不想挽留他,要想手下哪些个人可以替换他,这是你要考虑的。
关于离职预测,具体的特征、算法就不好给大家介绍的太多,算法相对比较简单,我给大家讲一讲我设计的思想。做离职预测是一件很难的事情,大家想一想就知道为什么。因为离职是一个人的动态行为,不是一个静态行为,不是一天到晚都想着离职,而是某一个事件之后,比如说离职风险曲线,只要把一个人按照时间排出来就是一个动态的曲线,有时候会高、有时候会低。这时候应该怎么做呢?很多预测都离不开这个基本原理,这个基本原理就是我总结的这个简单公式,很多动态预测都离不开这个简单的公式。
我们做预测就考虑两条,第一是α,第二是β。α就是《易经》中“不易”的东西,也就是最根本的东西。举个例子,假设我预测深南中路现在这个时间点的交通状况。最简单的预测是什么?今天是周六,现在是周六的11点20分,我预测11点20分周六的交通状况,最简单的预测办法是什么?把每个周六11点20分交通的状况拿出来,得一个平均值,这就是简单的α预测。但是α预测准不准?如果没有突发事件、没有黑天鹅,α是很准的,但是这个世界上充满了不确定性。不确定性下,我们需要动态的预测这个β,难就难在β的预测,α不难预测。β要做到实时数据收集和合理的特征选择,只有有限的特征、才能实时的推这个β。无论做离职预测还是做金融市场的交易分析,还是做其他行业的分析,都离不开这个公式。以前没有大数据的时候我做不了β的预测,以前只能给你看一看手相,以前做β预测是靠算卦,临时给你起一卦,看看这个β的方向到底是什么。绝大多数是α,那些人把情报收集好了,古代人就只能算卦,我起一卦看β往哪里走,然后把β和α综合在一起,这个是一个综合的参数。

我们现在跟古代最大的区别是什么?我们现在不需要依赖于算卦,我们依赖于实时的数据。以前算卦是没有办法的办法,输入太少了。输入太少的时候就创造一个输入,给你人为的制造一卦。这就是古代和现代的最大区别。现在不用算卦了,当你有数据就没有必要算卦了,什么数据都不给我的情况下才需要算一卦,帮助我找思想的方向。现在真正要想做好动态预测离不开这两条,真正难的是预测这个β,如果β预测好了,整个预测都会很准确。
我刚才说了,我们的离职预测非常非常准。我们有2000多个参数,如果不让我看最后模型中的数据,我都不知道哪个参数最后起的作用最大。每个人的作用是不一样的,这个人离职可能是因为短期待遇不满意,这个人离职可能是因为他想追求自己的职业发展,这个人离职可能因为两地分居的问题,这个人离职可能因为其他的问题,每个人的问题可能都不一样。我们只有看了这个具体特征,可以展现出来到底是什么原因去离职,真正的离职原因往往就是这个β,这是难点。
下面给大家介绍一下我们去年在KDD发的一篇文章。有的时候非常遗憾,我们认为真正非常有价值的东西往往不让发,很难发出来。不是说很难发出来,是很难被允许发出来。就跟做金融一样,发出来就没有价值了,只有不发出来、保留才有价值。这个也蛮有意思,这个问题相对来说是属于有用的知识。
我们做的事情很简单,我们做的事情是把所有市场上的招聘广告全部收下来。我们把所有招聘广告按照每个公司分门别类的收下来,比如说百度过去一年有1万个招聘广告,阿里有1万个,腾讯有1万个,每个招聘广告都是有时间点的,有不同的层级、有不同的时间点,针对不同的工作岗位,你把这些广告都收集下来。收集下来我们做模型分析,我们分析同一个状态不同公司不同的需求分布,又看不同公司招聘主题的分布,可以分析出来很多有意思的东西,比如说分析出来百度战略重点发生了重要改变。
当一个企业战略重点发生改变的时候,它首先需要人。当我有新战略的时候,举个例子,现在阿里想做量子计算了,阿里没有这样的人,还没有对外宣传我要做量子计算,但是我要对外宣布一定是做了的时候才做宣传,你要从基本的“不易”的逻辑,我首先没有这样的人,就要打这样的广告。当一个公司大量要打广告招量子计算的人的时候,哪怕没有对外宣布战略方向,这也告诉我了他的战略方向,要不然招那么多做量子计算的人干什么。虽然你没有宣布,我也知道你要新成立一个战略方向,这可以反映出来整个战略态势的转变。
对在座很多学生有好处的是,可以看到整个招聘市场对技能要求的变化,可以看到这个市场上对什么样的技能需求发生了重大的改变。这是我们当时的一个Motivation。我们通过整个招聘市场的情况,可以判断出不同公司对不同岗位、不同技能招聘需求的变化和趋势。这种变化和趋势可以帮助我们找到更好的Recruitment,可以帮助找工作的学生,告诉你们怎么做判断这些信息。将来可能有新的工作机会产生,说不定也是一个创业机会,可能有公司帮你润色一下简历,可以保证你通过第一关,要不然第一关都过不去,机器把你淘汰了。
你判断任何一个公司的战略变化,有很多方法去判断,因为我也做投资,我们既然做数据分析就不能跟别人一样拍脑袋,一定要有自己的逻辑,我们的逻辑无非是数据分析能力,一定要找到合理的数据分析来源,我们可以判断出来不同公司战略重点的变化,而且还可以判断出来不同公司面临的挑战。
举个例子,比如说我发现这个市场上突然很多企业都需要招深度数据分析人才或者AI的人才,我应该怎么办?我手里正好还有一些AI人才,我就担心了,提前给他们涨薪,提前做一做心理工作,避免被竞争对手挖走,因为市场需求增加了,这是很简单的可以看到的趋势性的东西。
从方法而言,我个人感觉,怎么去听一个演讲?我最喜欢听的是听他解决什么问题,至于具体的方法,我现在听的很少。具体方法我只要知道他为什么用这方法和他用这个方法的优点和缺点是什么就好了,再细节我就不听了,为什么?人的精力有限,注意力也有限,我把我的精力和注意力聚焦到我认为重要的部分。为什么具体的方法不听呢?第一,这么短的时间,如果你没有这部分的方法基础你也听不懂;第二,你将来真正用的时候,你已经知道这个方法的优点和缺点,想起来再读也来得及,我现在只需要知道有什么方法,它的优点和缺点是什么,当我面对具体场景的时候可以根据我的索引把这个方法找出来,这样就行了,这是我个人的体会。
要做到我刚才说的那些事情,还是有很多技术问题要解决,比如说你怎么看不同的招聘状态。我们有三个方面,一个是招聘状态,一个是招聘需求,还有一个是招聘的topic。招聘的topic可以从招聘的过程中产生,你通过这些东西可以判断一个企业内部招聘的状态变化和招聘的需求变化。最后,我们最后用Graph模型来解决,抽取出来招聘状态、招聘状态、招聘需求和招聘的Topic。
我给大家讲一下我们的结果。怎么去运用我们的结果?数据我已经告诉大家了,我们把市场上所有招聘广告的数据全部爬下来了。如果大家感兴趣,可以给我的学生发邮件,不用去爬了,我可以让学生给你们,没有问题。
我们收集了拉勾网从2014年到2015年的数据,我们现在有很多数据,不只是拉勾网,全世界各种招聘数据我们都收集了。我们去判断这些招聘状态,直接给大家讲一下这些结果。
比如说,看这个结果怎么看?这个结果首先可以看到这是一个分层蛋糕图,主要强调两条,一个是时间轴,2014年1月份到2015年的11月份,这是中国所有公司招聘人才专业技能的需求变化。浅灰色是什么?浅灰色具备基本数据分析人才的基本数据人才。深灰色是什么?深灰色是具备深度数据分析的人才,往往要求有博士学位或者多少年的数据分析的经验。浅灰色是刚出校门的本科生或者硕士生。其他都是做市场的,我们研究的主要都是高科技公司,没有研究传统性公司。
整个招聘市场的需求,对深度数据分析人才的需求,今年的数据我们已经分析出来了,今年这一块更大,2016年、2017年这一部分更大,包括人工智能这一部分非常大。这是浅层的数据分析人才,上面是深度的数据分析人才。
这里显示不同企业招聘状态的变化,第一个是百度,第二个是完美世界,包括京东、唯品会、腾讯这些公司。我们看到2015年的末端,无论百度对数据分析人才,阿里今年招了很多数据分析人才,这是2015年的数据。这边是京东、腾讯、百度、今日头条,可以看到大家的招聘趋势,还可以看到公司的战略变化。
公司的战略变化,举个简单的例子,你看百度,黄色的部分是从2014年到2015年百度招聘的人,招聘的都是属于移动搜索的人才,说明百度那个时间的重点在发展移动搜索、在发展百度地图。后面招聘的战略重点在发生改变,他在做无人车,在做各种各样的人工智能的东西。看到这个东西,大家会想,跟我有什么关系?跟你太有关系了。比如说你同样加入百度,你应该去哪个部门?当然越热的部门升的越快,工资涨得越高,薪水给的越高。你要看到任何公司战略重点的变化,当你面临选择的时候,你可以选择更好的方向。而且还可以做投资,你看各种企业的变化,比如说我们最近发现阿里招了不少做量子计算的,可以看到很多阿里量子计算的广告。一个公司的招聘往往走在战略宣布之前,他不用宣布我也知道他在干啥,因为逃不过这一关,你得招人,你不能说没有人就去做一件事情,而且也不可能偷偷招,不告诉大家在招人,那也不行,广告总是要打给人看的。所以,这是一个很好的方法,可以帮助你挖掘出来企业整个的战略变化方向。
让数据说话:员工价值评估
我们做的另外一个工作,对内部员工很多价值的评估。我给学生提个建议,未来你加入到很多企业之后,一定要记住不只是要靠专业技能。我把整个人分成三类:第一类叫做人员,第二类叫做人才,第三类叫做人物。
这三类的区别是什么?过去的企业,尤其是制造业,比如说很多流水线,用广东这边的话说是有很多拉妹,一条边上坐了很多人,那个叫拉妹,拉妹是人员。人员的基本要求是高效、守纪律,这是过去的企业。人员慢慢会被机器淘汰,现在人员都是做标准化、流程化的事务,所以人员的工资待遇会不断下降,人员工作机会可能都会丧失。
现在的企业需要什么?现在的企业需要人才。人才我把它定义成梯子型,首先要有专业的技能,比如说自然语言处理、深度学习算法用得很熟,我做数据挖掘很牛,各种算法都很懂,那你有一个深度。光有这个还不够,因为现在的工作越来越复杂化、越来越协同化,所以还要有团队精神。如果没有团队精神,你的技能再厉害也没有什么用,企业用不起来你,很难用你。所以首先要深度技能,还要有协同能力。
未来的企业需要什么?这个变相解释我为什么要研究人。未来的企业需要的是人物。过去的企业是人员堆积,现在的企业是人才堆积,未来的企业人物的密度会大量升高。人物是什么?人物首先必须是人才,必须要有深度的专业技能,必须要有很强的团结协同能力,最关键的是人物T字型上面还加了一个脑袋,人物要有领导力。刚才给大家介绍过,领导力是要有看未来的能力、看宽的能力、有带团队的能力,有风控意识和风控能力。
我判断任何一个组织、企业有没有价值,不管是一级市场还是二级市场,一级市场值不值得我投资,二级市场值不值得我去买股票。我就判断这个企业中有多少人物去了,在过去几个月中有多少人物沉淀下来了,千万别像乐视一样的,人物进去之后很快就跑了,这个信号比没有进去还糟糕。大家知道为什么吗?因为人物都是聪明人,不小心掉进一个坑,跑得比谁都快。你要招聘一个人物,要创造一个文化让这个人物真心留下来。如果这个公司像黑洞一样,很多过去认识的人物进去之后是一入豪门深似海,再也听不到了,那这个公司太牛了,我就买它的股票。谷歌就是这样,很多牛人进去之后再也听不到了,他也不走了,说明这些人首先认可。不能短期给高工资,原来100万,我给你200万,你别走了,但是人家会想,我在这里成长了吗?我在这里拿200万可以拿多久,如果只能拿一年,还不如赶快找一个地方可以拿150万,可以拿的时间长一点。我研究这些东西,我现在觉得非常有价值的一条是怎么预测人物、判断人物去哪儿了。
让数据说话:公司的圈子分析
最后简单说一下,我们去年还发了一篇文章,主要是做公司的圈子分析,这个圈子分析主要做一件事情,就是去判断各种企业之间这种招聘的相对的圈子。
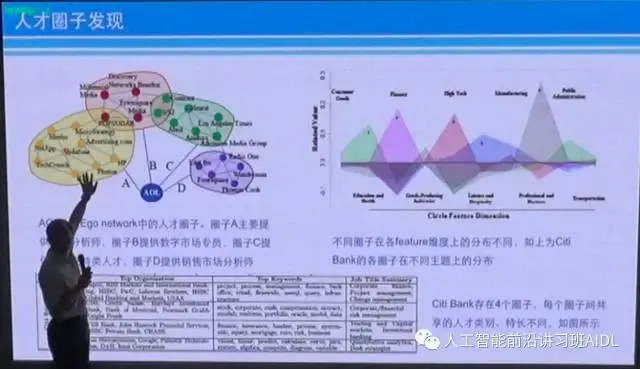
这个圈子的意思是什么呢?给大家解释一下就明白了,因为这个世界上说门当户对是很重要的,什么是门当户对?跟谈恋爱找朋友一样,企业也是门当户对。什么是企业的门当户对?举个例子,BAT招人不会直接从一个很烂的企业去招,他有门槛的。它的门槛是什么?比如说BAT相互挖人可以接受,他到京东去挖人可以接受,到新美大挖人可以接受,到头条挖人可以接受,但是一个莫名其妙没有听过的公司就不接受了,这就叫圈子。
比如说这个是AOL美国在线的公司。这个圈子怎么实现的?AOL做媒体的人才是世界一流的。但是它的IT人才很差,IT人才不会有谷歌、Facebook、linkedin的,那些地方付的工资他付不起。如果你是linkedin或者谷歌想跳槽的就不要往这里投简历了,因为他付不起你的工资,也不会招你,但是他会招聘IDG等等这种二线的公司。当一个公司突然招了很多HP的,如果你真的想去这个公司还不如去HP,先去HP再去这个公司就容易了。假设你想去Google,Google直接进进不了,先进微软,进微软之后进谷歌就容易了,你可以曲线作战,直接进Google进不去可以去微软,微软离Google还有一点距离。离的最近的是进Facebook,进Facebook之后微软马上就要你。顶尖公司的竞争就是这样的,跟男女生追男女朋友也是一个道理,你去追一个女生,这个女生不搭理你,你去追她的闺密,闺密搭理你了,她就紧张了。这个东西就是一个圈子,如果你真想去Google,一定搞清楚人家招聘的圈子是怎么回事。所以,这并不是什么难事情,如果你真想进Google,可以先进Facebook,或者你想进Facebook,进Google也一样的道理,实在不行就去二线的微软,去微软也是有难度的,不是那么容易。
Q & A
提问:老师您好,《易经》里面除了这三个原则之外,还有什么是可以运用到数据分析里面的?我也有研究过《易经》,但是没有太深入。
熊辉:要用到的多了,我在自己研究当中还用到一个概念“当位”,当位的概念我用的很多。判断一个企业、一个组织结构是不是稳定,我就看主要的骨架、承重墙,看那个位置的人是不是当位。任何一个组织像建筑物一样有承重墙,我要观察在这里做的人是不是符合这个位置的,如果这些人都是不当位的,那这个组织、这个企业就很难做好。
参考资料
作者:人工智能前沿讲习 https://www.bilibili.com/read/cv23345543/ 出处:bilibili