图像
颜色的相关概念
颜色是创建图像的基础,它通过光被人们感知。不同物体受光线照射后,一部分光线被吸收,其余的被反射后被人的眼睛接受并被大脑感知,称为我们所见的色彩。
表示一颜色光的度量采用三个物理量:色调(颜色:如红、黄等)、饱和度(深浅程度:如粉红、深蓝等)和亮度(明暗程度)。
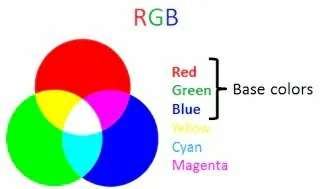
从理论上讲,任何一种颜色都可以用三种基本颜色按照不同的比例混合得到,也就是三原色原理(红R、绿G、蓝B)。
彩色模型
彩色模型是用来精确标定和生成各种颜色的一套规则和定义:RGB颜色模型、CMY(CMYK)颜色模型和YUV彩色模型。
RGB彩色模型:是工业界的一种颜色标准,是通过对红R、绿G、蓝B三个颜色通道的变化及他们相互之间的叠加来得到各式各样的颜色的,如彩色荧光屏通过发射三种不同强度的电子束,使屏幕内侧覆盖的红、绿、蓝光粉受激发光而产生各种不同的颜色。
YUV彩色模型:是被欧洲电视系统所采用的一种颜色编码方法,在现代彩色电视系统中,通常采用三管彩色摄像机或彩色CCD摄像机进行取像,然后取得的彩色图像信号经分色、分别放大矫正后得到RGB,在经过矩阵变换得到亮度信号Y和两个色差信号B-Y(即U)、R-Y(即V),最后发送端将亮度和色差三个信号分别进行编码,用同一个信道发送出去。这种色彩的表示方法就是YUV色彩空间表示,其重要性是它的亮度信号Y和色度信号UV是分离的。
RGB和YUV的换算:
1 | Y = 0.299R + 0.587G + 0.114B |
ITU-R BT.601-7 标准中拿到推荐的相关系数,就可以得到 YCbCr 与 RGB 相互转换的公式:
1 | Y = 0.299R + 0.587G + 0.114B |
图形和图像
图形:用矢量表示的图形,一般是工程作图等。
图像:用像素点描述的图,一般是摄像机和扫描仪等输入设备捕捉的实际场景。其属性一般包含分辨率、像素深度、图像表示法和种类等。
像素深度:是指存储每个像素所用的二进制位数。如一幅图像的图像深度是n位,则该图像的最多颜色数或灰度级为2的n次幂种。
分辨率:分为显示分辨率和图像分辨率。显示分辨率是指显示屏上能够显示出的像素数目(如手机屏幕是1080p,意思是手机屏幕上的像素点数目是1920X1080),图像分辨率是指组成一幅图像的像素密度,即每英寸多少个像素点(DPI,200dpi的设备扫描2x2.5英寸的彩色图片,得到图片的像素个数是400x500)。
图像的获取
将现实世界的景物通过物理设备输入到计算机的过程可以成为图像的获取:如用数码相机或数码摄像机进行拍照和录像。
一幅彩色图像可以看做二维连续函数f(x, y),将其变换为离散的矩阵表示,同样包含采样、量化和编码的数字化过程。
采样:分别在x和y轴上根据图像分辨率进行周期性采样,获得色彩值(亮度和色彩信息,会量化为像素点),假如DPI是200,获取2x2.5英寸的彩色图像,则采用后的像素矩阵大小是400x450,矩阵中的每个值代表一个像素点。
量化:对扫描得到的离散的像素点对应的连续色彩值进行A/D转换,每个采样点用N位的二进制表示;图像的数据量=总像素数x图像深度,如一幅400x450的256色图像大小是400x450x8b。
编码:把离散的像素矩阵按一定方式编成二进制码组,最后把得到的图像数据按某个图像格式记录在图像文件中;编码技术主要包括有损压缩和无损压缩,目前使用最广泛的压缩编码标准是JPEG标准;常用的图像文件格式有.jpeg、.png、.bmp、.gif等。
视频
帧/帧数(Frame/Frames)
简单的理解帧就是为视频或者动画中的每一张画面,而视频和动画特效就是由无数张画面组合而成,每一张画面都是一帧。帧数其实就是为帧生成数量的简称,可以解释为静止画面的数量。
一个帧(Frame)可能包含多个采样(Sample):一般每个视频帧中只包含一个视频采样,而音频帧中包含多个音频采样。
常见的视频帧有I、P、B帧。
I帧:关键帧,采用帧内压缩技术
P帧:向前参考帧,表示这一帧与上一帧的差别,属于帧间压缩技术
B帧:表示双向参考帧,压缩时既参考前一帧也参考后一帧,帧间压缩技术
一个 I 帧可以不依赖其他帧就解码出一幅完整的图像,而 P 帧、B 帧不行。P 帧需要依赖视频流中排在它前面的帧才能解码出图像。B 帧则需要依赖视频流中排在它前面或后面的帧才能解码出图像。
帧率(Frame Rate)
帧率(Frame rate) = 帧数(Frames)/时间(Time),单位为帧每秒(f/s, frames per second, fps)
帧率是用于测量显示帧数的量度,测量单位为“每秒显示帧数”(Frame per Second, fps)或“赫兹”(Hz),一般来说 FPS 用于描述视频、电子绘图或游戏每秒播放多少帧。
帧率的一般以下几个典型值:
24/25 fps:1 秒 24/25 帧,一般的电影帧率;
30/60 fps:1 秒 30/60 帧,游戏的帧率,30 帧可以接受,60 帧会感觉更加流畅逼真。
85 fps 以上人眼基本无法察觉出来了,所以更高的帧率在视频里没有太大意义。
分辨率
指视频成像产品所形成的图像大小或尺寸。
| 标准 | 分辨率 |
|---|---|
| QCIF | 176x144 |
| CIF | 352x288 |
| DV(NTSC) | 704x576 |
| DV(PAL) | 720x576 |
| HD(720p) | 1280x720 |
| 1080p | 1920x1080 |
| 4K | 3840x2160 |
码率(比特率/bps)
也就是比特率,比特率是单位时间播放连续的媒体(如压缩的音频和视频)的比特数量。比特率越高,带宽消耗得越多。
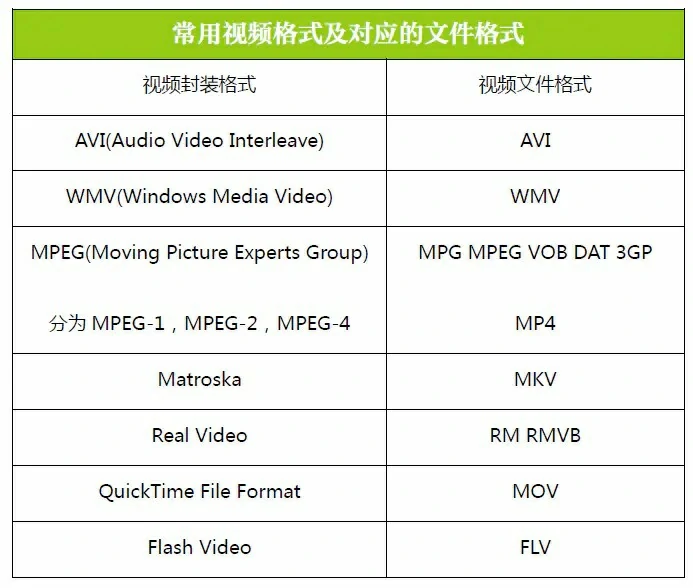
封装格式
视频封装格式,简称视频格式,相当于一种储存视频信息的容器,它里面包含了封装视频文件所需要的视频信息、音频信息和相关的配置信息(比如:视频和音频的关联信息、如何解码等等)。一种视频封装格式的直接反映就是对应着相应的视频文件格式。
编码格式
通过压缩技术,将原始视频格式的文件转换成另一种视频格式文件。编码的目的是压缩数据量,采用编码算法压缩冗余数据。
无损压缩:RGB → YUV(色域转换)
有损压缩:MPEG(MPEG-2、MPEG-4)、H.26X(H.264/AVC、H.265/HEVC)
(几乎所有压缩都是有损压缩,损失了原始图像信息)
压缩编码
数字视频信息的数据量很大,如每帧1280x720像素点,图像深度为16位,每秒30帧,则每秒的数量量高达1280x720x16x30/(8x1024x1024)=52.7MB。为了解决此问题,必须对数字视频信息进行压缩编码:帧内压缩和帧间压缩。
帧内压缩:也称为空间压缩,近考虑本帧的数据,即把单独的图像帧当做一个静态图像进行压缩,如M-JPEG编码;
帧间压缩:视频具有时间上的连续特征,可以利用帧内信息冗余,即视频数据的连续前后两帧具有很大的相关性,或者说前后两帧信息变化很小的特点实现高效的数据压缩,通常采用基于运动补偿的帧间预测编码技术。
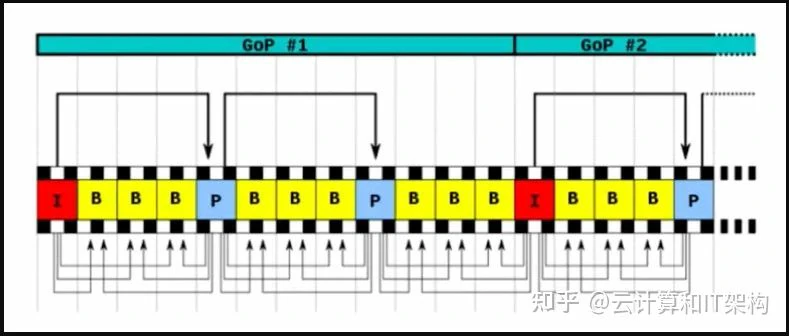
帧的种类分为I帧、P帧和B帧,I帧是关键帧只采用帧内压缩技术,在视频快进时只能寻找I帧;P帧是基于上一个I帧或者P帧的差异采用帧间压缩获得的帧;B帧是双向两个帧采用帧间压缩获得的帧。编码时选定一个I帧,基于此I帧生成一个P帧,然后在此IP帧中间插入若干个B帧,其存储顺序为IPBBB,在播放时正常的顺序是IBBBP。
GOP
GOP即Group of picture(图像组),指两个I帧之间的距离。参考周期(Reference)指两个P帧之间的距离。一个I帧所占用的字节数大于一个P帧,一个P帧所占用的字节数大于一个B帧。所以在码率不变的前提下,GOP值越大,P、B帧的数量会越多,平均每个I、P、B帧所占用的字节数就越多,也就更容易获取较好的图像质量;Reference越大,B帧的数量越多,同理也更容易获得较好的图像质量。
DTS和PTS
DTS:Decode Time Stamp,主要用于标示读入内存的比特流在什么时候开始送入解码器中进行解码。
PTS:Presentation Time Stamp,主要用于度量解码后的视频帧什么时候被显示出来。
由于B帧需要前后的帧才能解出图像,所以可能一个视频中帧的显示顺序是I B B P,但我们在解码B帧时需要P帧的信息,所以在传输的视频流中的顺序是I P B B。这时候就体现出每帧都有 DTS 和 PTS 的作用了。DTS 告诉我们该按什么顺序解码这几帧图像,PTS 告诉我们该按什么顺序显示这几帧图像。
例如:
Stream: I P B B
PTS: 1 4 2 3
DTS: 1 2 3 4
数字视频信息
是指活动、连续的图像序列,一幅图像称为一帧,帧是构成视频信息的基本单元。数字视频使用的彩色模型是YCbCr,此模型接近YUV模型,Cb代表蓝色差,Cr代表红色差信号,由于人眼对色度信号的敏感程度远不如对亮度信号敏感,所以色度信号的采样频率可以比亮度信号的取样频率低一些,以减少数字视频的数据量,这种方式称为色度子采样。目前常用的色度子样模式是:
4:4:4,指每条扫描线上每4个连续的采样点取4个亮点样本Y、4个色度样本Cr和4个色度样本Cb,这就相当于每个像素都用3个分量样本表示;
4:2:2,指每条扫描线上每4个连续的采样点取4个亮点样本Y、2个色度样本Cr和2个色度样本Cb;
4:1:1,指每条扫描线上每4个连续的采样点取4个亮点样本Y、1个色度样本Cr和1个色度样本Cb;
4:2:0,指在水平和垂直方向上每2个连续的取样点上取2个亮度样本Y、1个色度样本Cr和1个色度样本Cb,即对2X2点阵的4个采样点采样4个亮度样本和各1个色度样本;H.261、H.263和MPEG-1视频标准均使用这种取样格式。
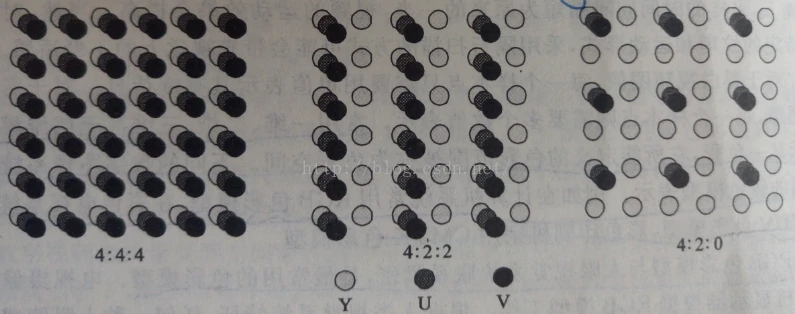
字幕
根据字幕的存放方式可以把内嵌字幕(硬字幕)和外挂字幕(软字幕)。
内嵌字幕(硬字幕)
把字幕文件和视频流压制在同一组数据里,像水印一样,无法分离。特点是兼容性好,对一些播放器无需字幕插件需求;缺点是,修正难度大,一旦出错必须整个视频文件重新制作,因为无法分离,限制了用户对字体风格个人喜好的修改。
外挂字幕(软字幕)
把字幕文件单独保存为srt、ASS、SSA或SUB格式,只需与视频文件名相同,播放时自动调用,也可用MKV进行封装;缺点是,需要字幕插件支持,一些播放器在某些配置下无法渲染;优点是,修正便捷,可以随意修改字体风格等。
详细拓展
编码格式详解
H.26X 系列
由国际电传视讯联盟远程通信标准化组织(ITU-T)主导,包括 H.261、H.262、H.263、H.264、H.265。
H.261
H.261产生的时候,由于各国的电视制式并不统一,因此在H.261中规定了一种中间格式CIF,在编码时首先需要将需要编码的格式转换为CIF格式,然后进行传输,接收端进行解码后在转化为各自的格式。H.261规定的CIF格式视频的亮度分辨率为352×288,QCIF格式的亮度分辨率为176×144。
H.261编码所采用的技术:
帧内编码/帧间编码判定:根据帧与帧之间的相关性判定——相关性高使用帧间编码,相关性低使用帧内编码。
帧内编码:对于帧内编码帧,直接使用DCT编码8×8的像素块。
帧间编码/运动估计:使用以宏块为基础的运动补偿预测编码;当前宏块从参考帧中查找最佳匹配宏块,并计算其相对偏移量(Vx, Vy)作为运动矢量;编码器使用DCT、量化编码当前宏块和预测宏块的残差信号;
环路滤波器:实际上是一个数字低通滤波器,滤除不必要的高频信息,以消除方块效应。
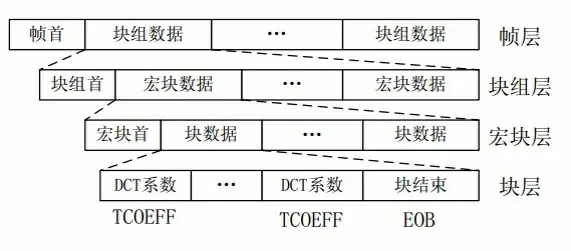
H.261的码流采用了分层结构:
H.262
等同于 MPEG-2 第二部分,使用在 DVD、SVCD 和大多数数字视频广播系统和有线分布系统中。
H.263
H.263是在H.261的基础上做了改进和增强,相对于H.261有着更好的压缩比,并且在H.261的CIF和QCIF的格式基础上增加了Sub-QCIF、4CIF和16CIF。
| 格式 | 分辨率 |
|---|---|
| CIF | 352x288 |
| QCIF | 176x144 |
| Sub-QCIF | 128x96 |
| 4CIF | 704x576 |
| 16CIF | 1480x1152 |
在视频信源编码上,相比H.261,从每个宏块一个运动矢量扩展为对每一个8*8的像素块分配一个运动矢量,并且开始支持1/2像素精度的运动矢量。同时增加了算数编码和双向预测来进一步提升压缩比。
| H.261 | H.263 | H.264 | |
|---|---|---|---|
| 运动矢量 | 每个宏块分配一个运动矢量 | 每个8*8的像素块分配一个运动矢量 | 可针对44和1616的像素块分配运动矢量 |
| 像素精度 | 整像素 | 1/2像素 | 1/4像素、1/8像素 |
| 预测模式 | I帧、P帧 | I帧、P帧、B帧,增加了双向预测 | 帧内预测提供44和1616两种分块方式;帧内预测预测了所有的变化系数 |
| 熵编码 | 变长编码 | 变长编码、算术编码 |
H.264
H.264,等同于 MPEG-4 第十部分,也被称为高级视频编码(Advanced Video Coding,简称 AVC),是一种视频压缩标准,一种被广泛使用的高精度视频的录制、压缩和发布格式。该标准引入了一系列新的能够大大提高压缩性能的技术,并能够同时在高码率端和低码率端大大超越以前的诸标准。
H.264在最初制定时,仅支持8bit采用,色度采样使用4:2:0,仅考虑了大部分通用的视频处理和传输场合,没有考虑特殊的处理,如源视频采样精度超过了8bit,色度采样使用了4:2:2或4:4:4,这些视频处理能力都超出了H.264的处理范围,后来又推出了H.264 FRExt。
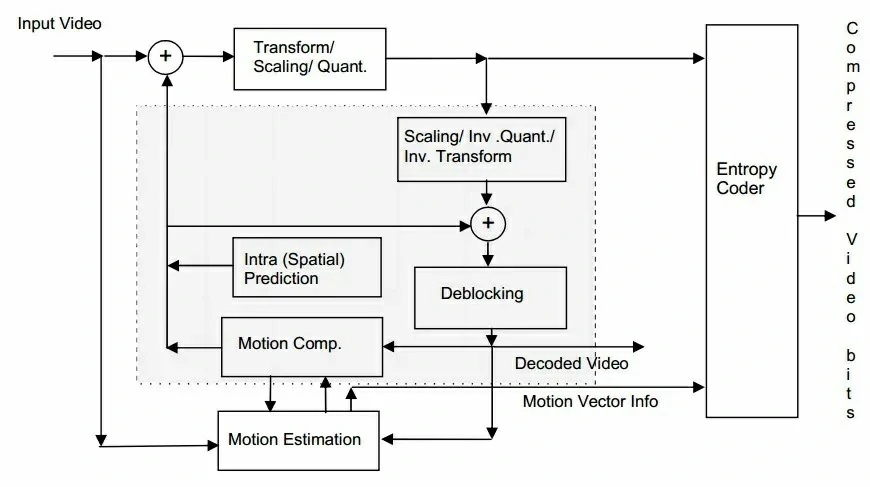
H.264整体的编码框架上,依旧采用了块结构的混合编码框架;整个结构包括两个部分,网络抽象层(NAL)和视频编码层(VCL)。视频的每一帧被分为一个或多个slice进行编码,每一个slice包含多了宏块(Macroblock),其中宏块是H.264基本的编码单元,这种宏块包含一个1616亮度块+两个88的色度块+其他一些宏块头信息。整个编码的框架如下图:
H.264相比原来的编码标准有着更多的改进,在编码中,H.264的每一个宏块会被分割为多种不同大小的子块进行预测编码,帧内预测采用的块的大小可能为1616,也可能为44,帧间预测采用的块有着7种不同的大小,分别是1616、168、816、88、84、48和44,针对预测残差数据进行的变换编码采用了44或8*8的变换块。在熵编码中提供了CAVLC(Context Adaptive VariableLength Coding)和CABAC(ContextAdaptive Binary Arithmatic Coding)
帧内预测
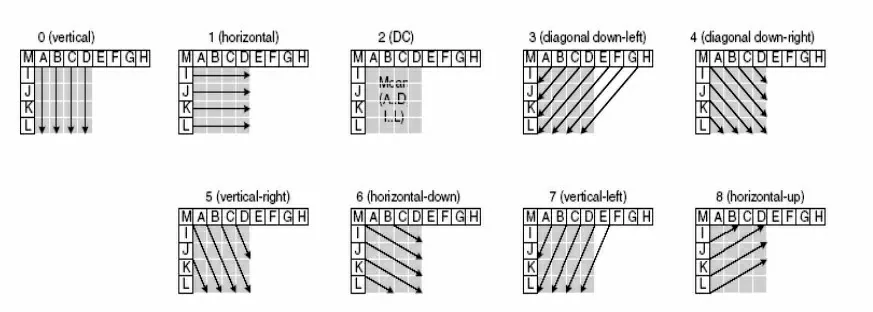
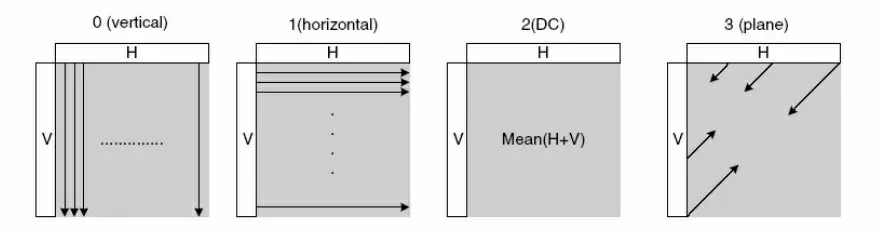
预测编码的思路简单来说就是指编码的实际值和预测值之间的差异,对于帧内预测来说是利用空间冗余,即利用帧内像素的相似性,来获得残差,如果对残差进行编码要比对实际值进行编码的码流小的多。例如在一个88的亮度分量的实际像素值中,左侧是实际值,中间是预测值,右侧是残差。在H.264中,使用空间域的左方与上方的相邻像素预测当前编码的像素值,如果一个宏块是Intra宏块,即宏块采用帧内预测,其亮度分量有两种分割模式,一个1616像素块或者16个44像素块,其中对于每个44像素块有9中预测模式,对于1616的像素块有4种预测模式。由于H.264的一个宏块包含了2个88的色度分量,对于色度分量的预测方式与16*16的亮度分量相同。
4*4像素块的预测方式
16*16像素块的预测方式
帧间预测
H.264的帧间预测方法类似于H.263等前期标准的方法,在具体的算法上进行了一定的改进,相比H.263增加了更多的宏块划分模式,从1616到44,并且使用了非整像素来增加运动矢量精度。
帧间预测的宏块分割方式
H.265
H.265,被称为高效率视频编码(High Efficiency Video Coding,简称 HEVC)是一种视频压缩标准,是 H.264 的继任者。HEVC 被认为不仅提升图像质量,同时也能达到 H.264 两倍的压缩率(等同于同样画面质量下比特率减少了 50%),可支持 4K 分辨率甚至到超高画质电视,最高分辨率可达到 8192×4320(8K 分辨率),这是目前发展的趋势。
MPEG 系列
由国际标准组织机构(ISO)下属的运动图象专家组(MPEG)开发。
MPEG-1 第二部分:主要使用在 VCD 上,有些在线视频也使用这种格式。该编解码器的质量大致上和原有的 VHS 录像带相当。
MPEG-2 第二部分:等同于 H.262,使用在 DVD、SVCD 和大多数数字视频广播系统和有线分布系统中。
MPEG-4 第二部分:可以使用在网络传输、广播和媒体存储上。比起 MPEG-2 第二部分和第一版的 H.263,它的压缩性能有所提高。
MPEG-4 第十部分:等同于 H.264,是这两个编码组织合作诞生的标准。
其他,AMV、AVS、Bink、CineForm 等等,这里就不做多的介绍了。
封装格式详解
AVI 格式,对应的文件格式为 .avi,英文全称 Audio Video Interleaved
是由 Microsoft 公司于 1992 年推出。这种视频格式的优点是图像质量好,无损 AVI 可以保存 alpha 通道。缺点是体积过于庞大,并且压缩标准不统一,存在较多的高低版本兼容问题。
DV-AVI 格式,对应的文件格式为 .avi,英文全称 Digital Video Format
是由索尼、松下、JVC 等多家厂商联合提出的一种家用数字视频格式。常见的数码摄像机就是使用这种格式记录视频数据的。它可以通过电脑的 IEEE 1394 端口传输视频数据到电脑,也可以将电脑中编辑好的的视频数据回录到数码摄像机中。
WMV 格式,对应的文件格式是 .wmv、.asf,英文全称 Windows Media Video
是微软推出的一种采用独立编码方式并且可以直接在网上实时观看视频节目的文件压缩格式。在同等视频质量下,WMV 格式的文件可以边下载边播放,因此很适合在网上播放和传输。
MPEG 格式,对应的文件格式有 .mpg、.mpeg、.mpe、.dat、.vob、.asf、.3gp、.mp4 等等,英文全称 Moving Picture Experts Group
是由运动图像专家组制定的视频格式,该专家组于 1988 年组建,专门负责视频和音频标准制定,其成员都是视频、音频以及系统领域的技术专家。MPEG 格式目前有三个压缩标准,分别是 MPEG-1、MPEG-2、和 MPEG-4。MPEG-4 是现在用的比较多的视频封装格式,它为了播放流式媒体的高质量视频而专门设计的,以求使用最少的数据获得最佳的图像质量。
Matroska 格式,对应的文件格式是 .mkv
Matroska 是一种新的视频封装格式,它可将多种不同编码的视频及 16 条以上不同格式的音频和不同语言的字幕流封装到一个 Matroska Media 文件当中。
Real Video 格式,对应的文件格式是 .rm、.rmvb
是 Real Networks 公司所制定的音频视频压缩规范称为 Real Media。用户可以使用 RealPlayer 根据不同的网络传输速率制定出不同的压缩比率,从而实现在低速率的网络上进行影像数据实时传送和播放。
QuickTime File Format 格式,对应的文件格式是 .mov
是 Apple 公司开发的一种视频格式,默认的播放器是苹果的 QuickTime。这种封装格式具有较高的压缩比率和较完美的视频清晰度等特点,并可以保存 alpha 通道。
Flash Video 格式,对应的文件格式是 .flv
是由 Adobe Flash 延伸出来的一种网络视频封装格式。这种格式被很多视频网站所采用。
编码格式和封装格式的关系
可以把「封装格式」看做是一个装着视频、音频、「编码方式」等信息的容器。一种「封装格式」可以支持多种「编码方式」,比如:QuickTime File Format(.MOV)支持几乎所有的「编码方式」,MPEG(.MP4)也支持相当广的「视频编解码方式」。当我们看到一个视频文件名为 test.mov时,我们可以知道它的「视频文件格式」是 .mov,也可以知道它的视频封装格式是 QuickTime File Format,但是无法知道它的「视频编解码方式」。那比较专业的说法可能是以 A/B 这种方式,A 是「视频编解码方式」,B 是「视频封装格式」。比如:一个 H.264/MOV 的视频文件,它的封装方式就是 QuickTime File Format,编码方式是 H.264。
IPB帧详解
I 帧(Intra coded frames):I 帧图像采用帧内编码方式,即只利用了单帧图像内的空间相关性,而没有利用时间相关性。I 帧使用帧内压缩,不使用运动补偿,由于 I 帧不依赖其它帧,所以是随机存取的入点,同时是解码的基准帧。I 帧主要用于接收机的初始化和信道的获取,以及节目的切换和插入,I 帧图像的压缩倍数相对较低。I 帧图像是周期性出现在图像序列中的,出现频率可由编码器选择。
P 帧(Predicted frames):P 帧和 B 帧图像采用帧间编码方式,即同时利用了空间和时间上的相关性。P 帧图像只采用前向时间预测,可以提高压缩效率和图像质量。P 帧图像中可以包含帧内编码的部分,即 P 帧中的每一个宏块可以是前向预测,也可以是帧内编码。
B 帧(Bi-directional predicted frames):B 帧图像采用双向时间预测,可以大大提高压缩倍数。值得注意的是,由于 B 帧图像采用了未来帧作为参考,因此 MPEG-2 编码码流中图像帧的传输顺序和显示顺序是不同的。
也就是说,一个 I 帧可以不依赖其他帧就解码出一幅完整的图像,而 P 帧、B 帧不行。P 帧需要依赖视频流中排在它前面的帧才能解码出图像。B 帧则需要依赖视频流中排在它前面或后面的帧才能解码出图像。
这就带来一个问题:在视频流中,先到来的 B 帧无法立即解码,需要等待它依赖的后面的 I、P 帧先解码完成,这样一来播放时间与解码时间不一致了,顺序打乱了,那这些帧就需要DTS 和 PTS来播放。