- CS231n - 迁移学习之分割、定位与检测
概念定义
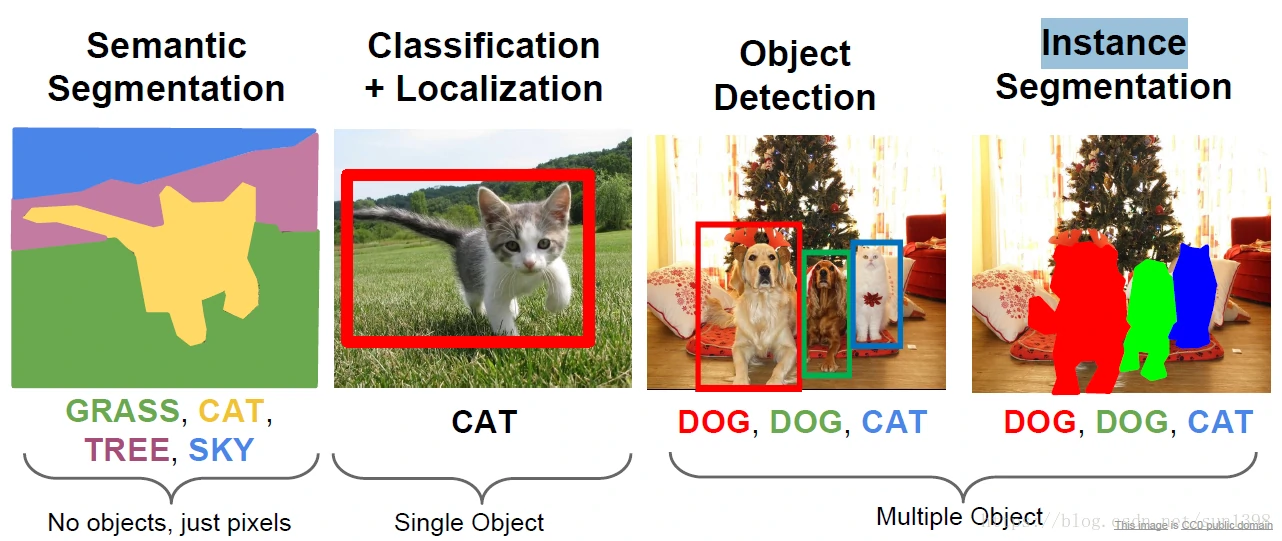
语义分割将图像不同层次都用轮廓分割出来,实时分割问题更多的是多任务问题,在不同层次上实时的进行图像分割。
分类与定位,分类问题简单的降图像中识别的物体种类输出,定位给出不同物体所在图片中的坐标,可能需要标注框来框出物体所在目标,而分类+定位问题就是两者皆有
目标检测,与分类问题进行比较,主要区别是多物体分类与定位,解决地问题可能更复杂。
不同的图像任务所需的网络架构不同,分类+定位——目标检测——语义分割,问题困难程度不断加深。
分类与定位
基本分类与定位
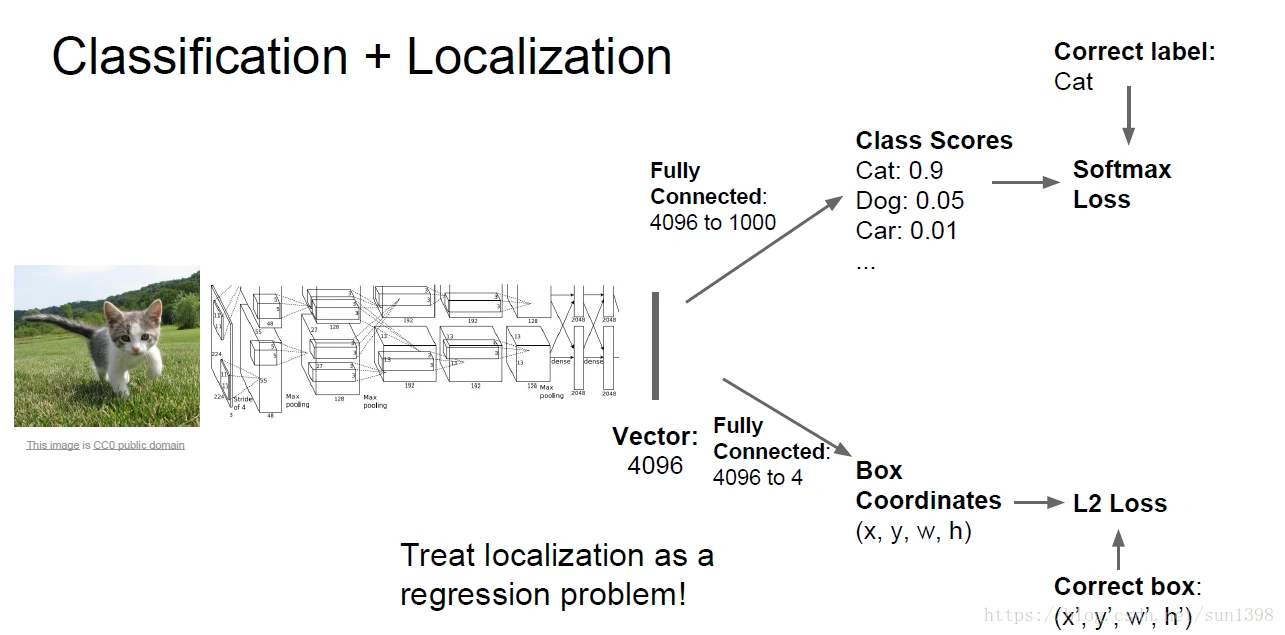
将分类定位问题看成一个回归问题,使用L2范数欧式距离来计算损失函数。
下载别人已经前训练过的模型(AlexNex、VGG、GoogleNet),当然自信有时间有装备也可以自己训练模型。得到class scores的全连接层,分类层得到C类。
新建一个回归层(regression head),其实也是全连接层,输出类所在的位置框。
然后通过一张张图像的训练,最后完成分类与定位的训练。
回归有两类回归:不定类回归(class-agnostic regresar)和特定类回归(class-specific regresar),不论使用什么结构,我们在全连接层都使用相同的结构和权值来得到边界框(bounding box)。不定类回归使用1个4坐标Box,特定类回归得到C*4坐标Boxes
回归层可以选择在全连接层后、卷积层后,根据不同网络模型进行选择尝试。
人类姿态识别
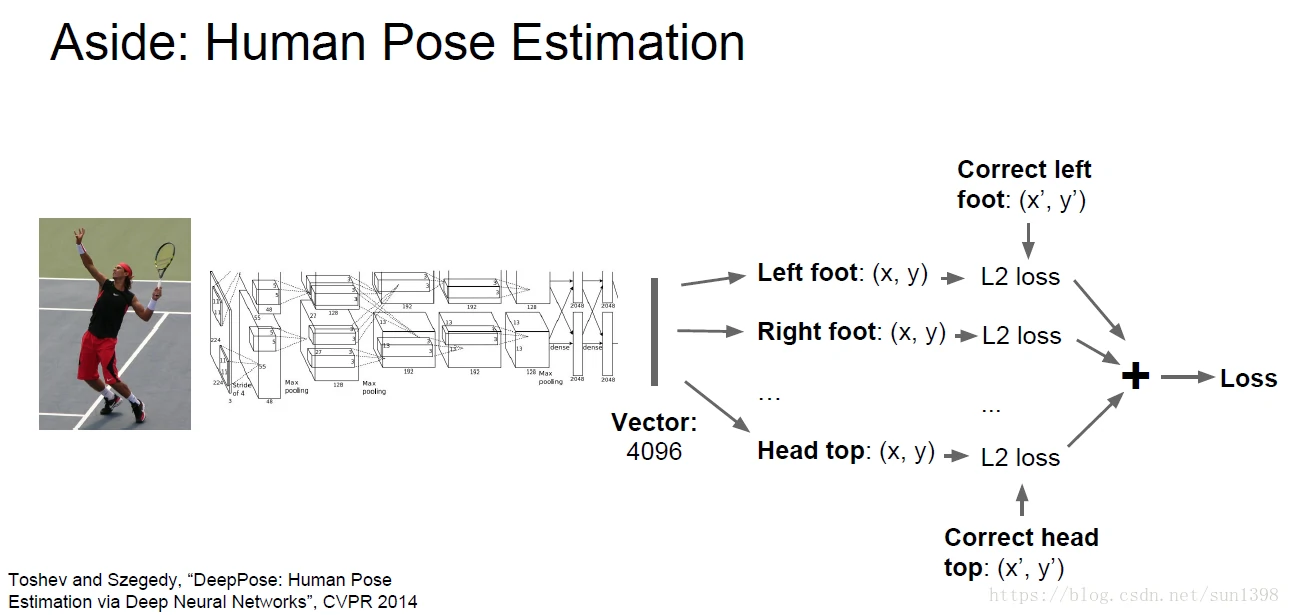
人类姿态识别,主要根据人姿态由关节决定,通过网络计算出不同关节的位置14连接点(joint positions),从而实现运动姿态识别。
定位基本姿态后,可以根据不同的姿态再去分类识别不同的运动动作。
滑动窗口识别–overfeat网络

通过对一张图片进行整张图片进行分割,形成不同的图片,分别对图片进行分类与定位,得到不同框内的概率与定位框,再通过算法将概率和框,整合成一个整体。
缺点是计算量大,需要对每一块不同的层都进行计算,其中有很多的数据冗余。
当然可以使用YOLO算法,对不同坐标只看一次,将图片分割成N张小窗口,最后输出看成是不在是一个M的输出,而是N*M的矩阵,加快计算。
检测
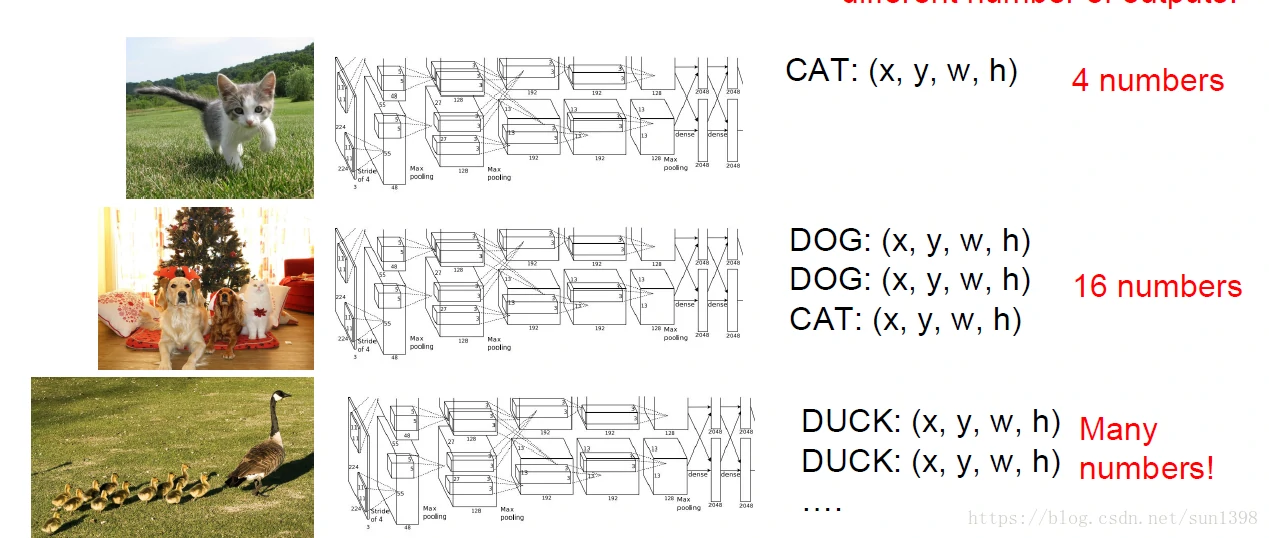
检测问题是复杂的,实际上由于检测目标的不确定性,很难将其转换为一个回归问题。
可以将图片一部分输入分类器,形成分类问题,将检测问题转换成分类与定位问题,将会变得简单得多。
但问题是需要将不同的大小、不同的位置都试验一遍,将极大地消耗计算资源。
解决方法:历史上就使用HOG(梯度分布直方图)来进行不同位置的图像特征提取;DPM继承这种方法,线性分类器来进行分类。
Region Proposals

原理是输入图像,然后输出所有可能存在目标的位置,不可知目标分类器,不关心对象具体的类别,精度不高,但是运算速度非常快
在图中寻找整体相似的色块,形成候选框:选择性搜索,从像素的角度出发,将相似颜色和纹理相邻的像素合并,然后不断的合并,形成大框,在不同的尺寸上进行操作,极大地减少检测的计算量
R-CNN

选择感兴趣的区域位置直接进行CNN分类
缺点是训练复杂,下载模型,增加不同层,训练处理速度非常非常慢,测试速度也非常慢。
Fast R-CNN
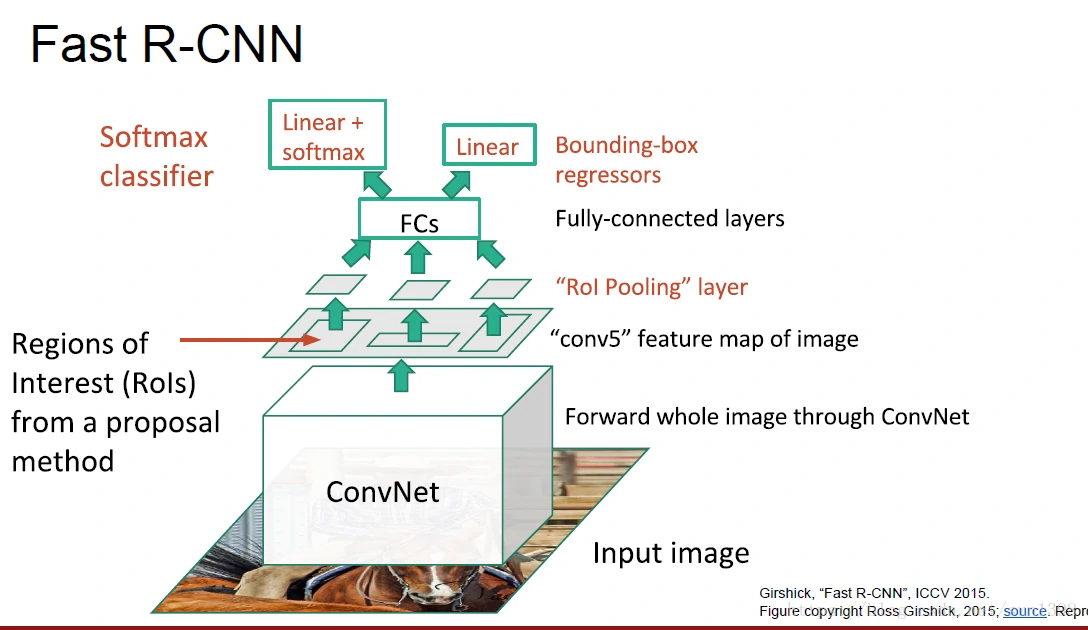
- 改善点1:感兴趣区域的提取使用卷积的方式,增加速度
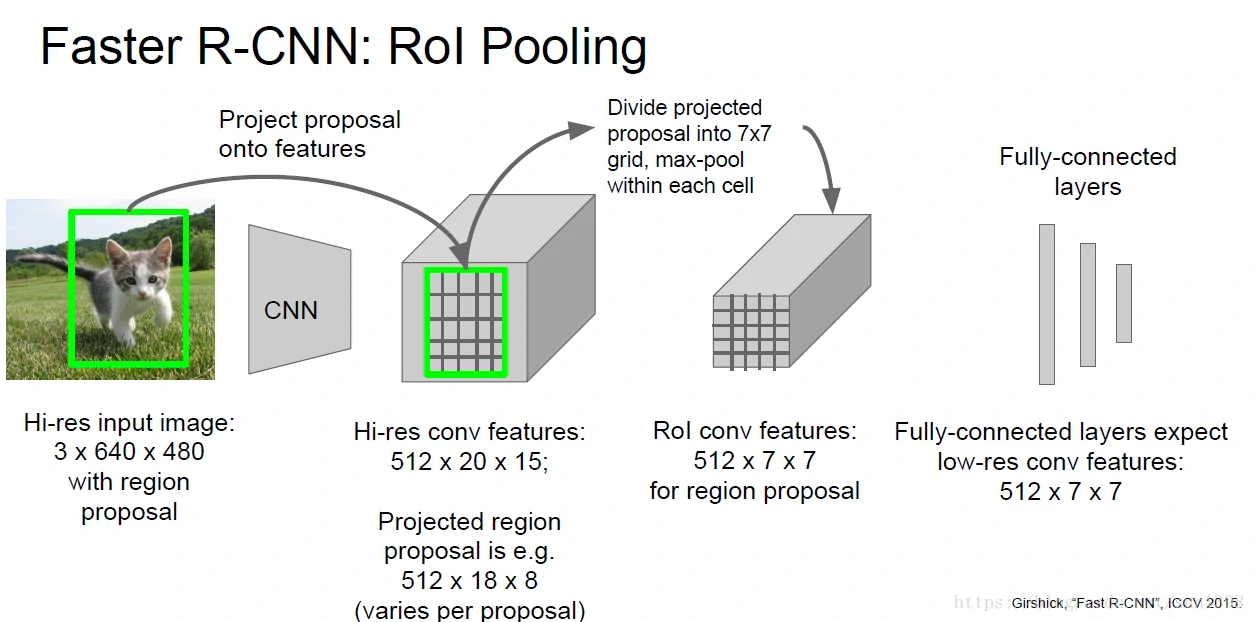
- 改善点2:增加Rol池化层,降低数据量,使用softmax替代SVM。
Faster R-CNN
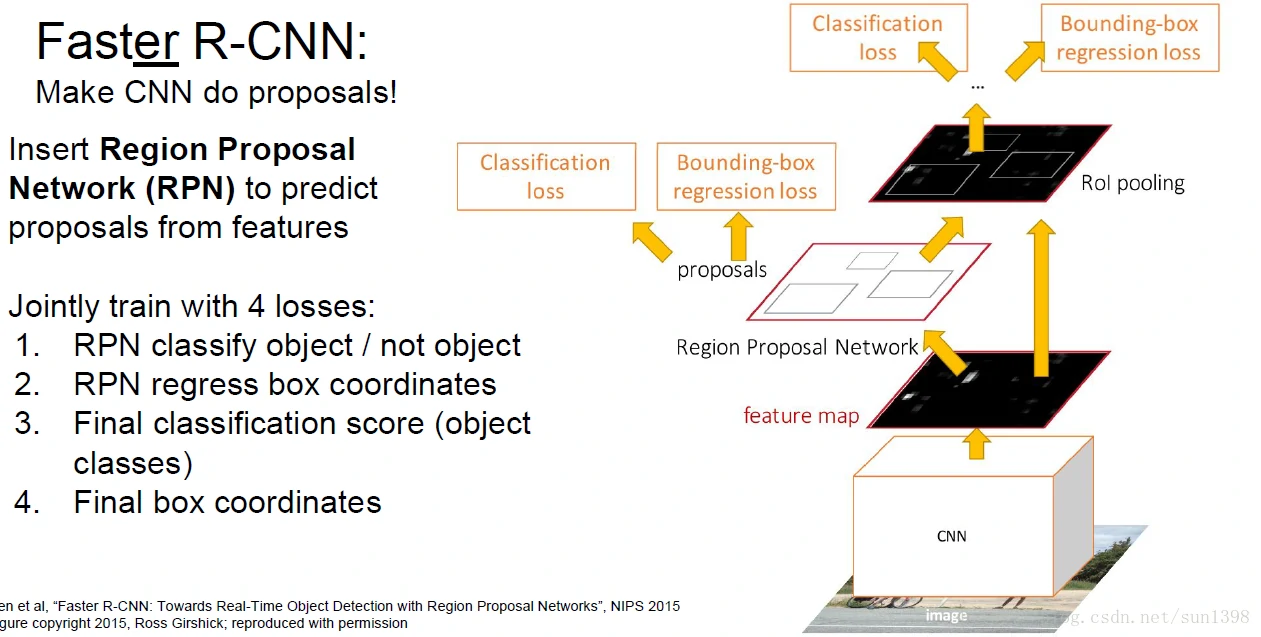
- 增加感兴趣区域网络(CNN)的方式来提取特征,训练一层新的模型,加快速度,准确率依旧很高。
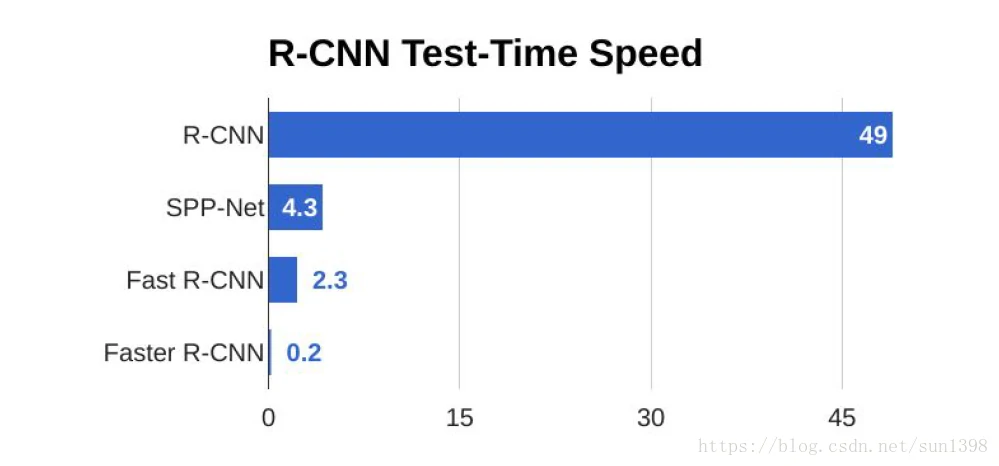
- 四种常用方法测试速度对比,显而易见RCNN速度太慢,尽量不要使用。
YOLO/SSD
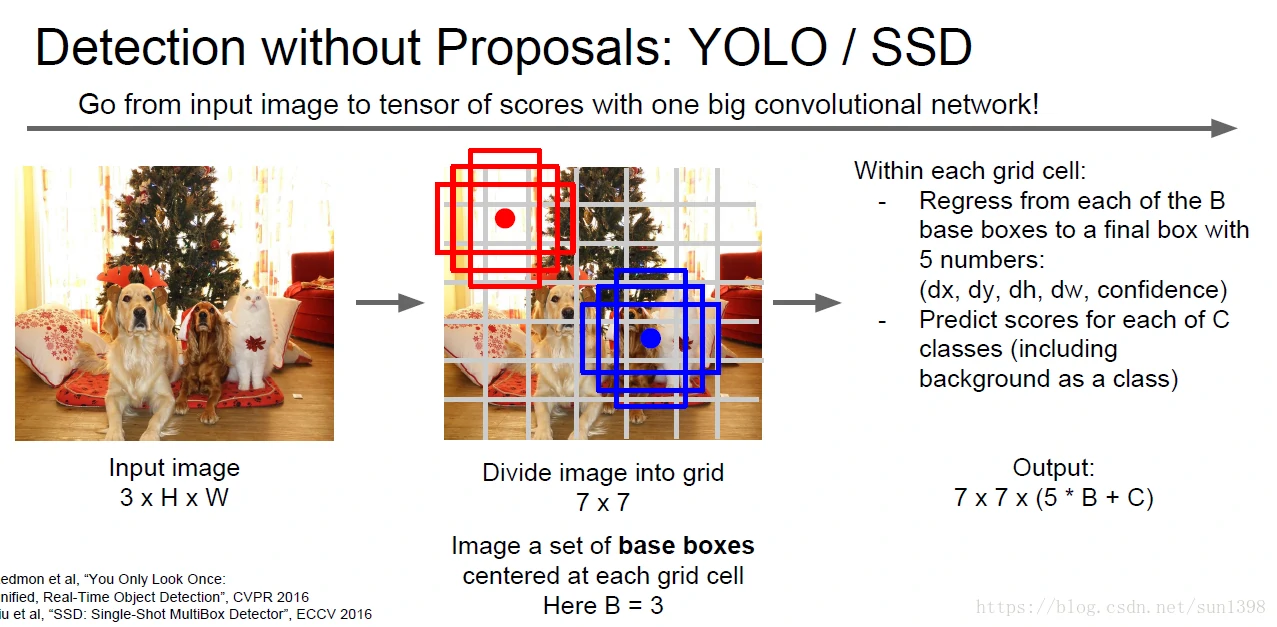
当然以上的方法还是做不到实时处理,提出了只看一次算法,将图片等分成N块,输出除了包括边界,还增加了一个置信概率,概率最大区域为中心,通过扩大旁边不同的区域,最终实现目标的识别。
处理速度大大增快,能够实现实时处理的要求,
缺点,虽然速度增快了,但是当图片内有很多目标物体时,将很难准确识别所有目标,准确率降低。所以实际应用中,根据不同情况选择哪种方法。
复杂密集检测–其实没看懂,得去看论文
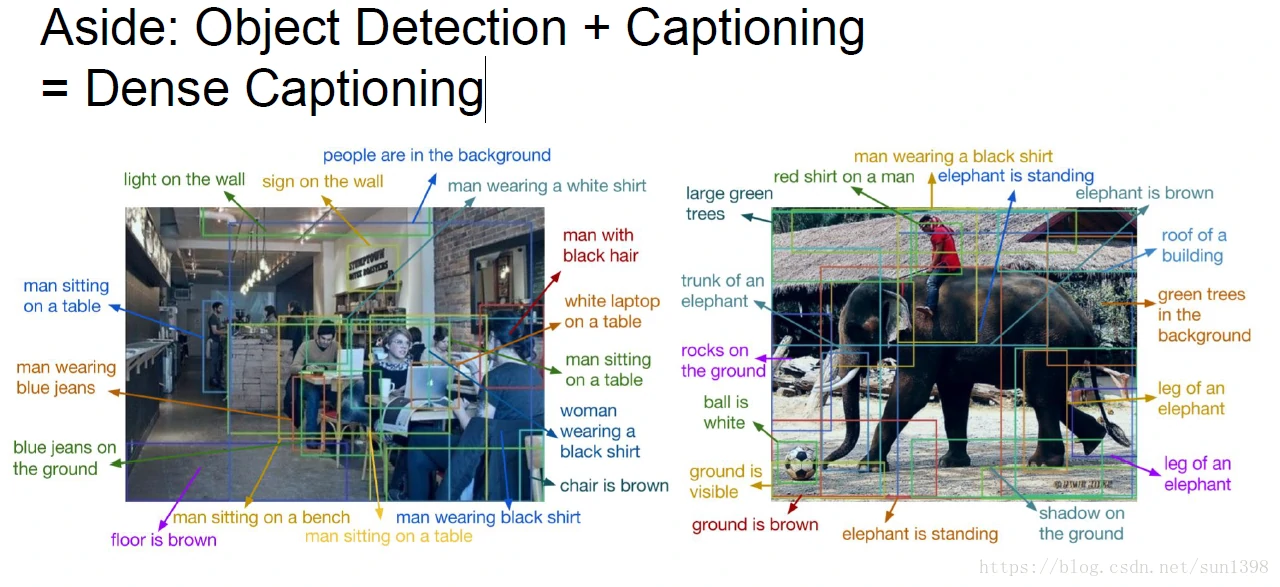
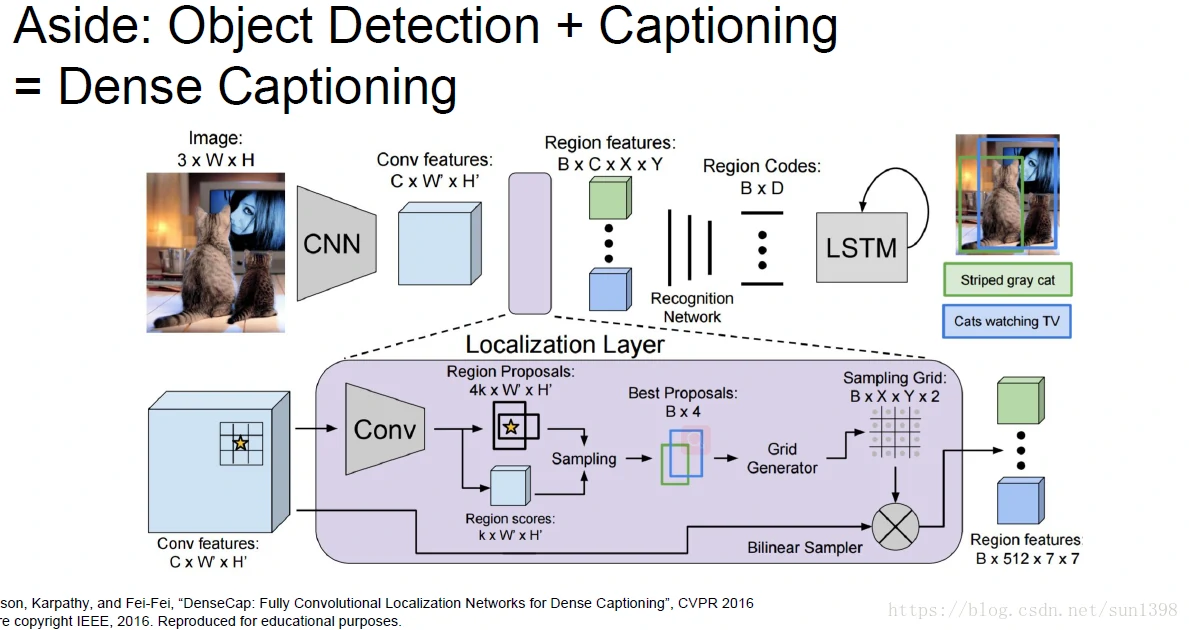
实时图像分割
Mask-RNN
