- CS231n - RNN
RNN总体分类
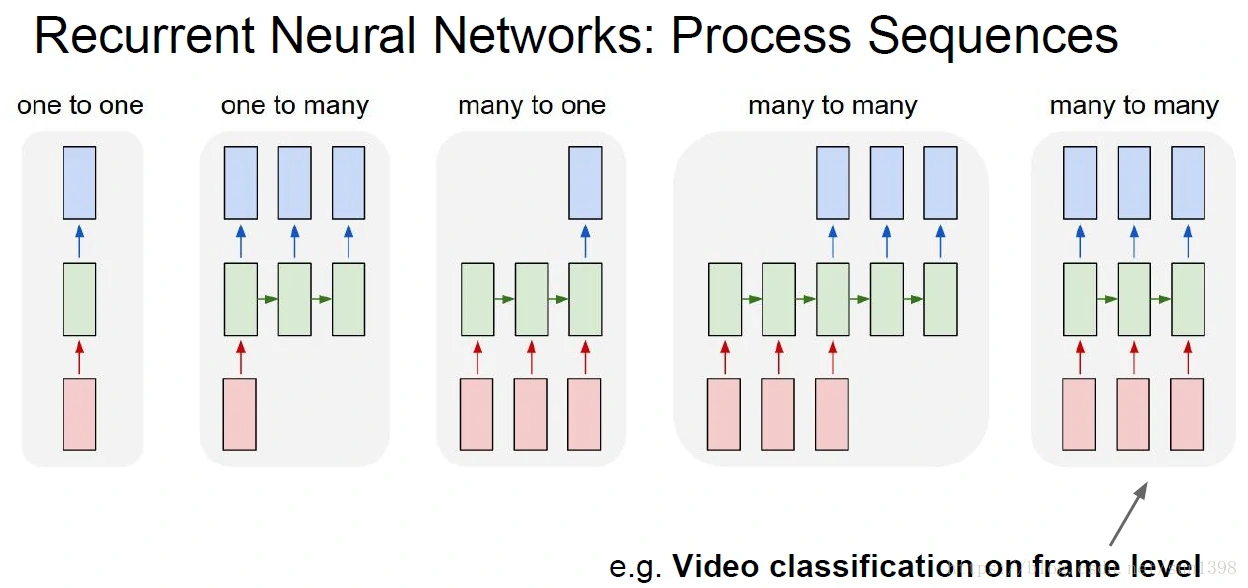
循环神经网络,包含了多种结构,适用不同的情况,处理不同的序列,主要分类为:
one2one:Vanilla neural network,最简单的循环神经网络结构
one2many:Image Captioning(图像标注),用于图像生成多个序列的单词
many2one:Sentiment Classification(情感分类),用于将多文本生成一个结果
many2many:machine translate(机器翻译),用于多序列生成多序列
many2many:帧级别的视频分类
RNN基本结构
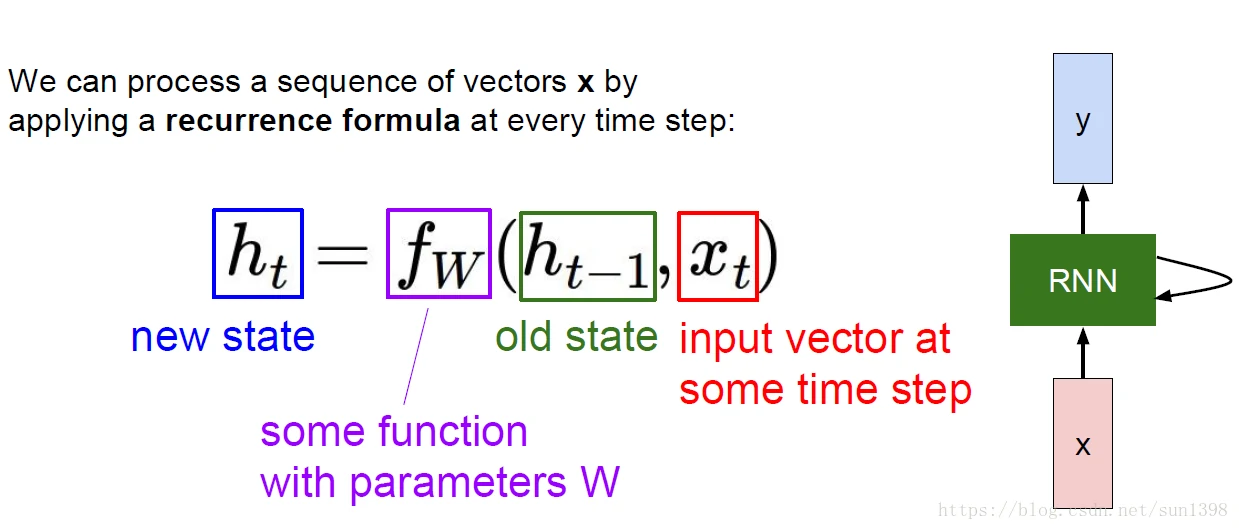
循环的结构,将t-1的状态和t的输入经过函数f,主要是参数乘以两个状态生成新的当前状态,增加了对以前的状态的依赖性。
在每一个步骤选用的都是相同的更新函数和线性参数。
以tanh为例,RNN的函数与参数如下,tanh在RNN是常用的激活函数:
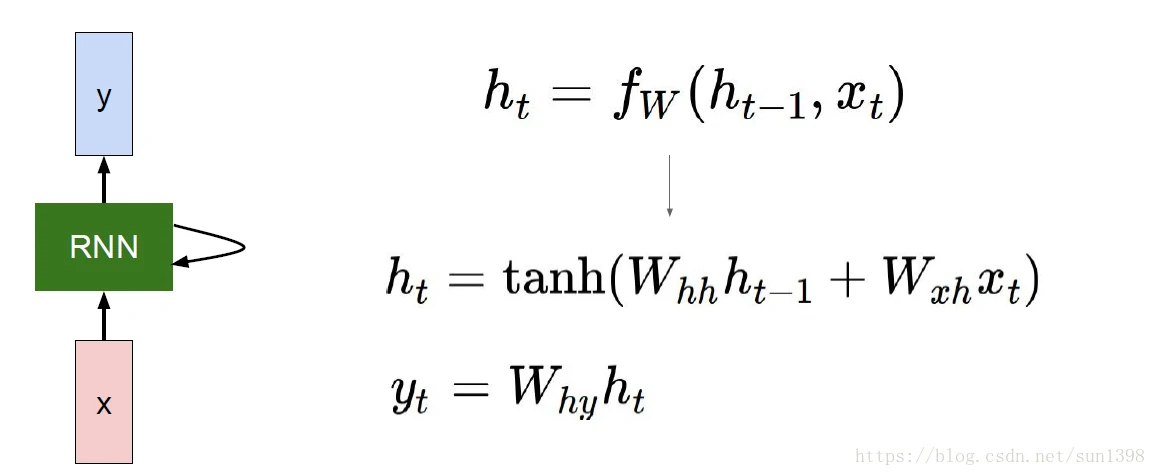
- many2many的结构,一般在得到当前的状态后,乘以系数矩阵W_hy使用softmax得到y分类,与实际的y结果做比较,得到当前的损失函数,然后叠加到最终的损失函数来进行后向传播
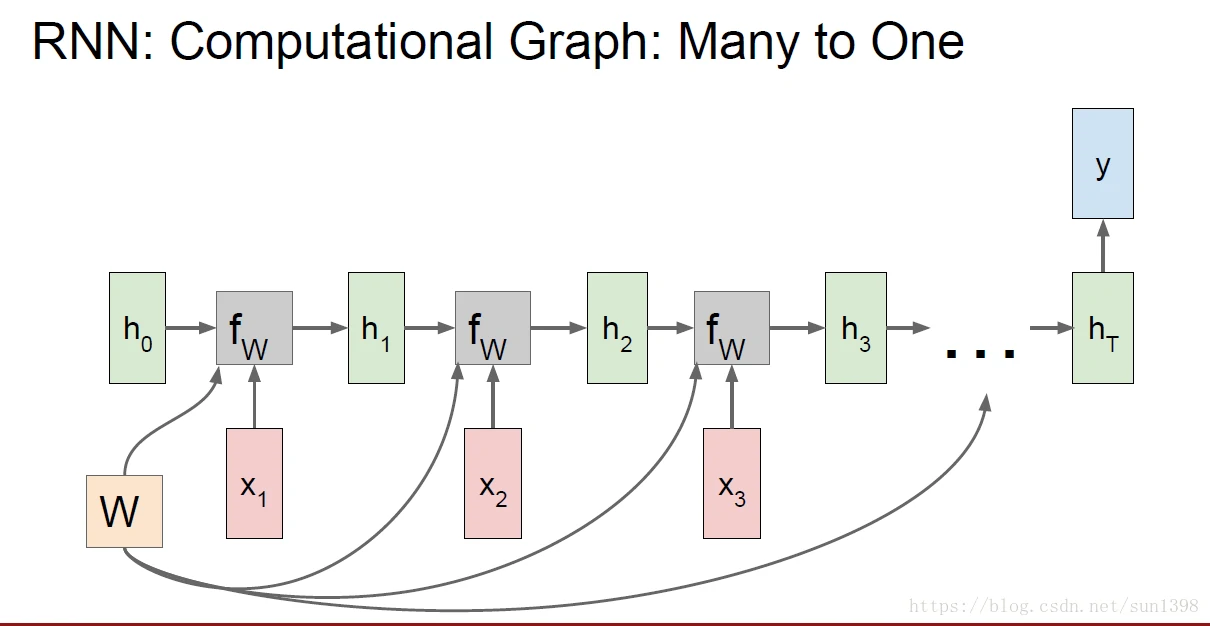
- many2one的结构,Sentiment Classification(情感分类),用于将多文本生成一个结果
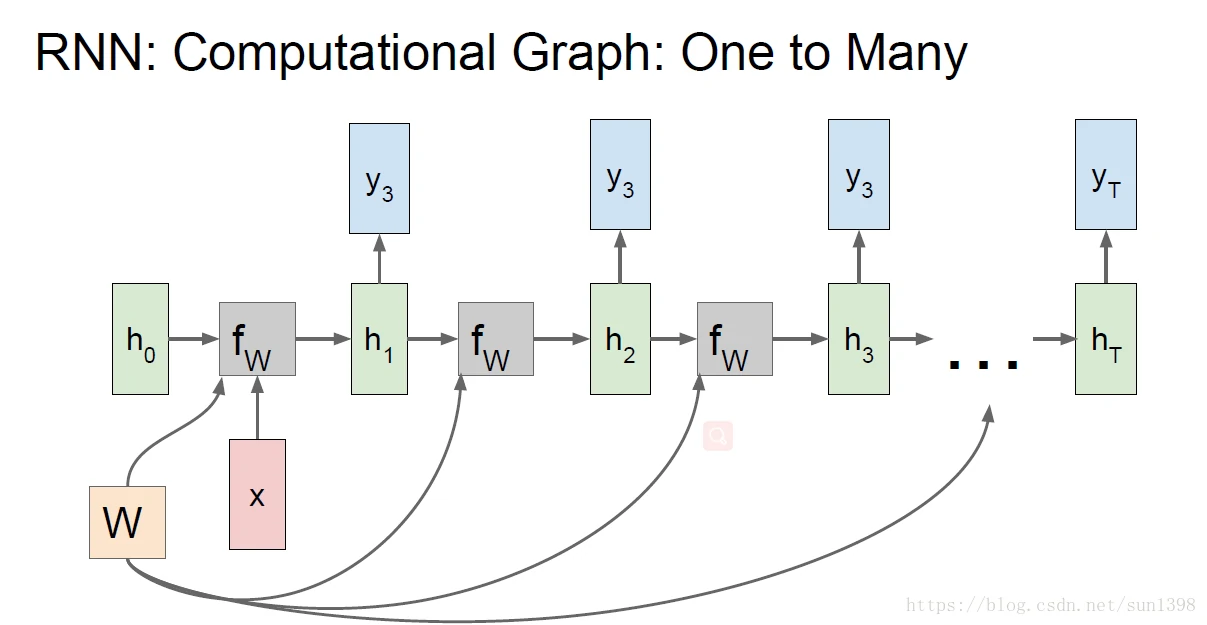
- one2many的结构,Image Captioning(图像标注),用于图像生成多个序列的单词
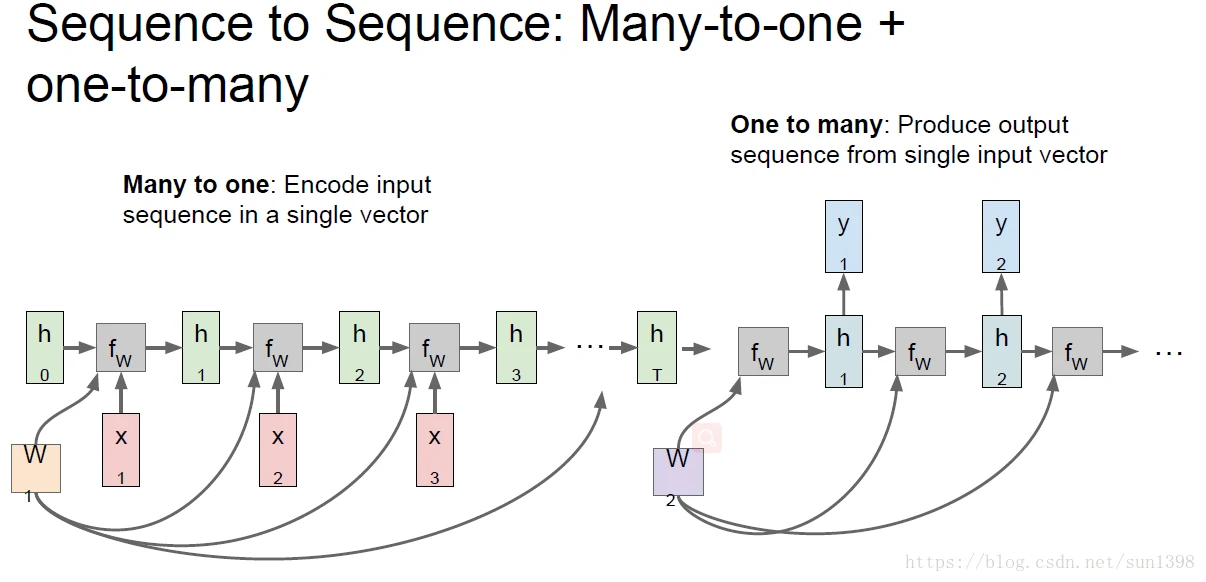
- many2one+one2many的结构,使用多序列生成单一序列,再通过单1序列经过另一组参数W_hh2来生成多组数据。
字符级别语言模型
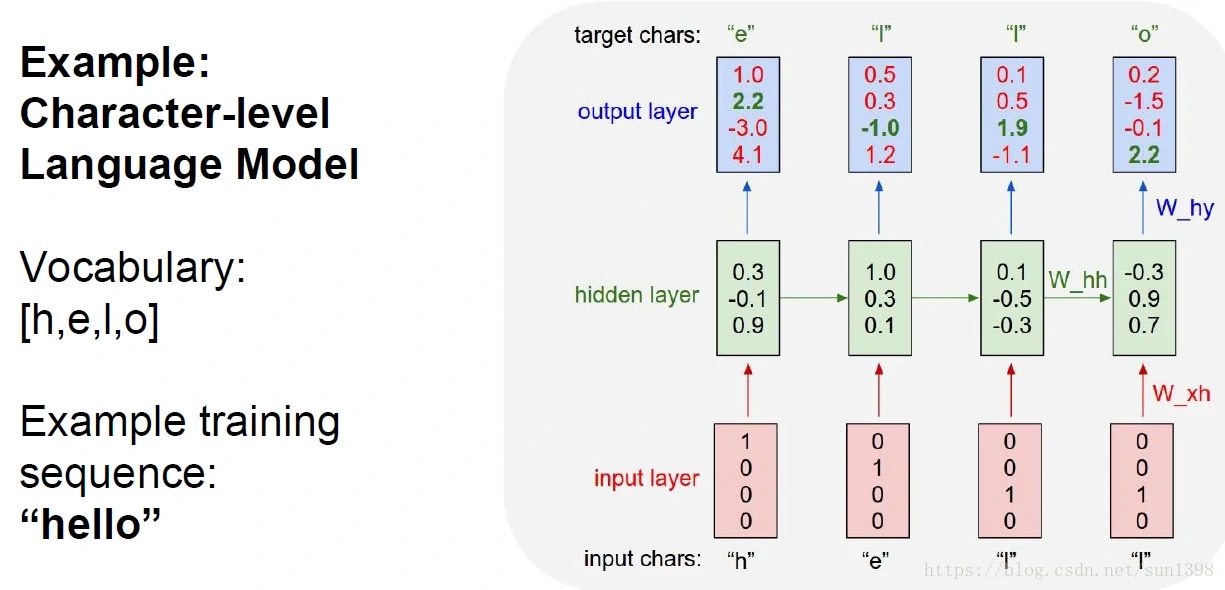
- 隐藏状态值h,输出层y,再通过softmax生成字符表的概率,one-shot(独热和非独热编码),然后通过反向传播训练W参数
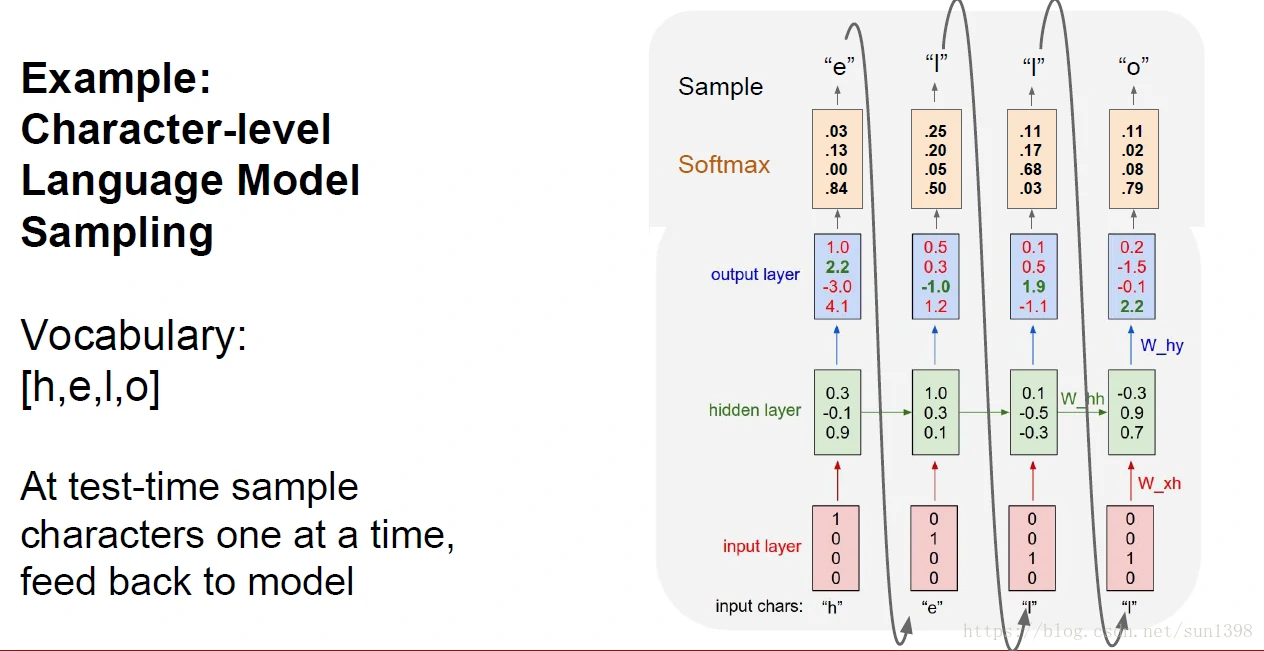
- 根据当前的字符推测下一个字符的概率,“hello”,输出层是softmax,然后将输出预测的字符作为下一级的x输入。
反向传播
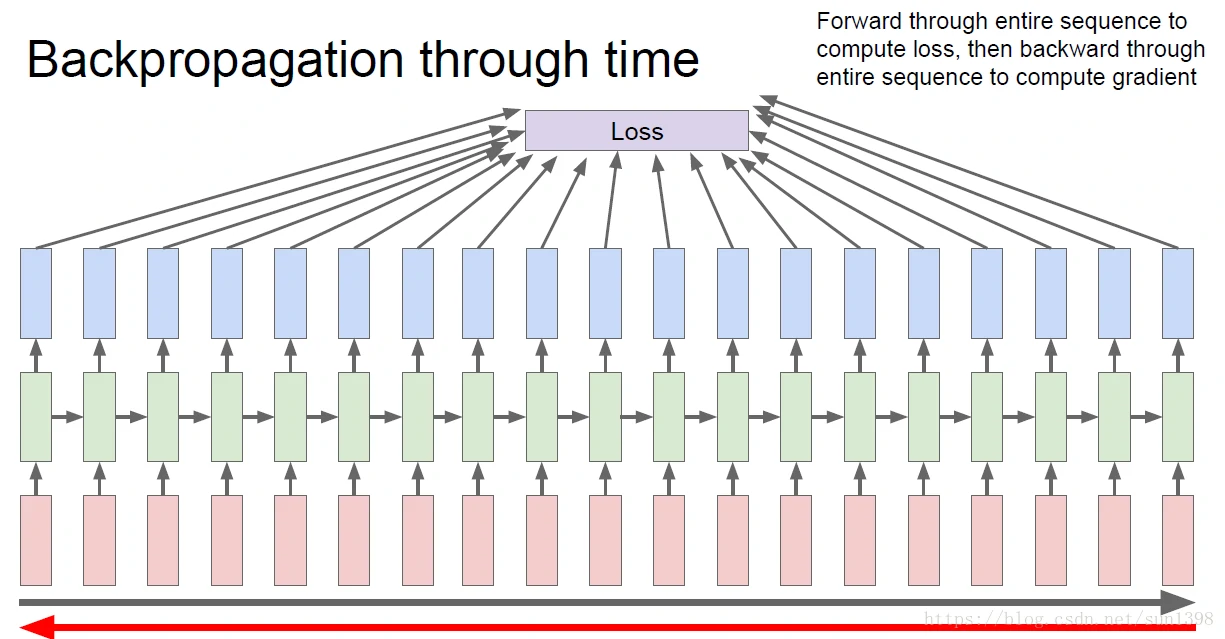
- 最初始的想法是对整个网络进行前向传播,但是对所有网络进行反向传播。但是对于一个实际的RNN的网络,一个网络序列的深度无法确定,可能会很长,实际上不适合对所有的网络进行反向传播
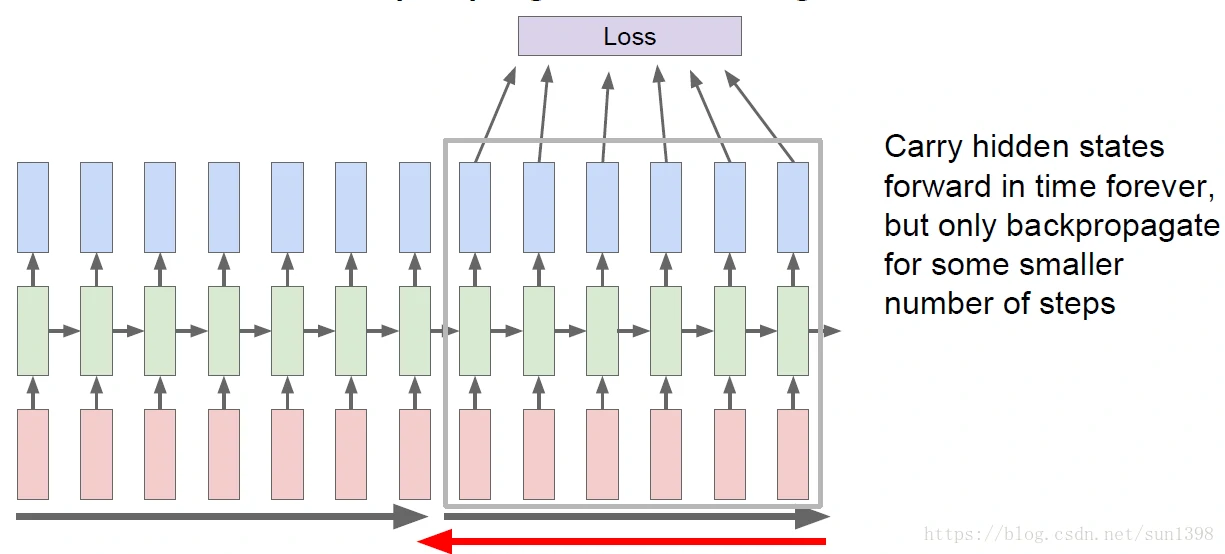
通常会采用对一个块模块进行反向传播,对所有的级别进行前向传播,但是只对一个很小数量的序列进行反向传播。
这样有利于反向传播的稳定性,一方面避免反向传播太长导致梯度消失和梯度爆炸,另一方面保证序列间相关性。
RNN模仿威廉莎士比亚进行写作
RNN模仿进行代码写作
- RNN能够模仿出注释,但函数很多意义并不明显。
图像标注:结合CNN和RNN
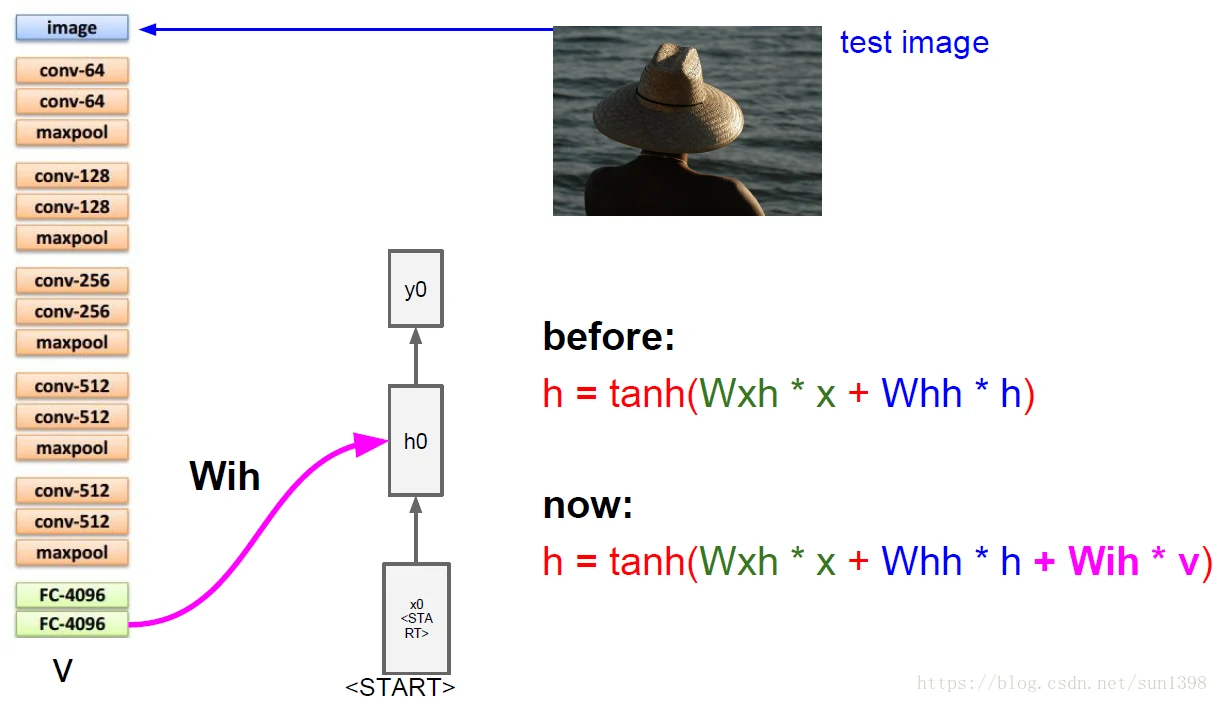
将CNN最后的全连接层和分类层抛弃,将矩阵结果输出到RNN序列上,生成对应的单词进行序列标注
CNN起到提取图像特征的作用,成功进行标注的案例如下:

图像标注-注意力模型
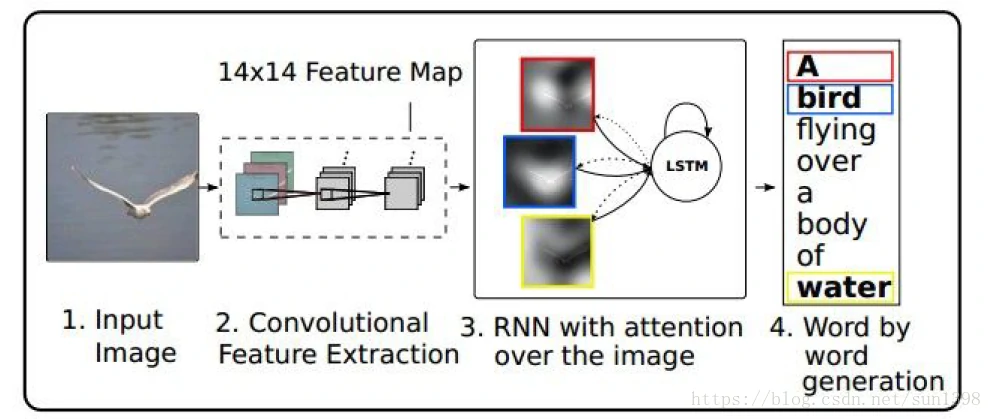
- 让网络能够识别出该集中注意力区域,使用LSTM进行RNN分类。
普通RNN
多层次RNN
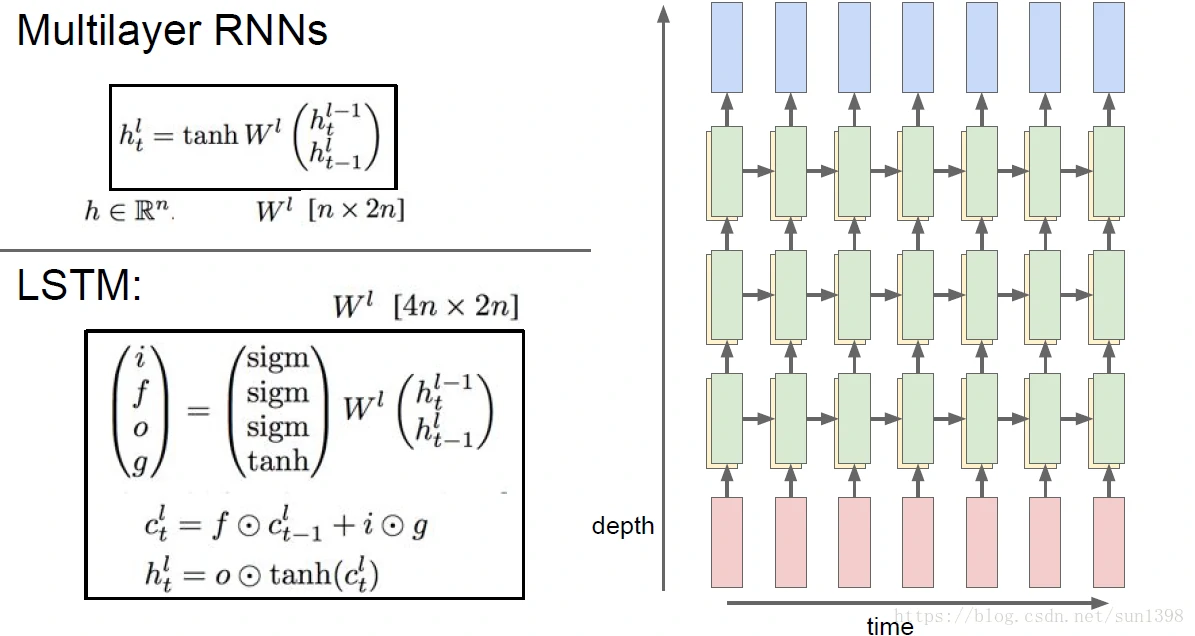
- 增强网络效果,增大规模,实际上并不一定就比单层的RNN更好,每1层都使用相同的权重W_hl参数。
vanilla网络计算图
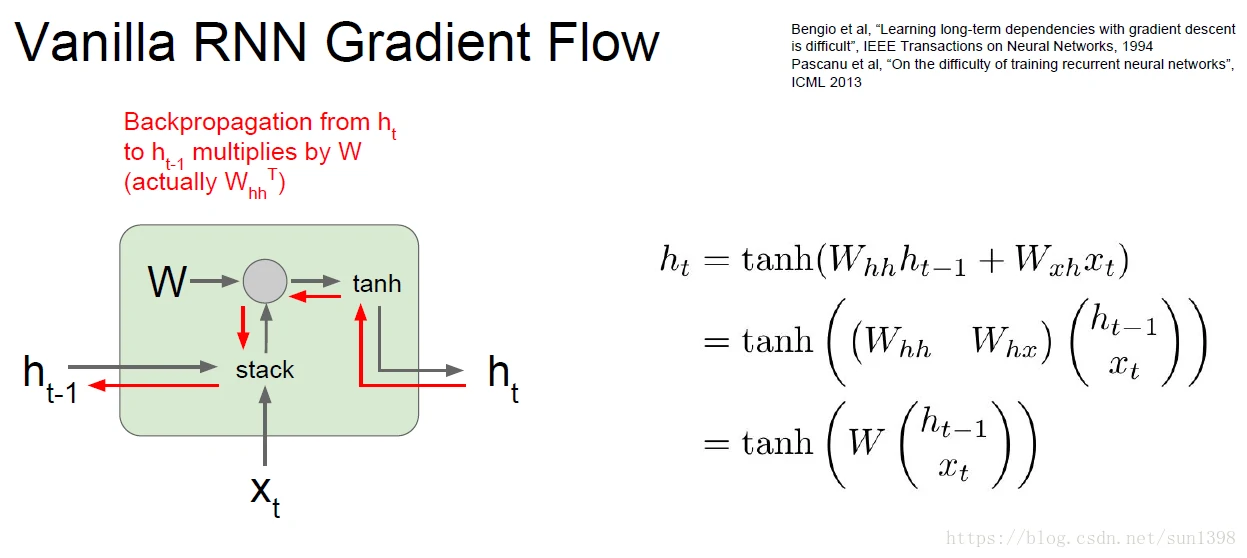
- 可以使用变换的方式,将Whh和Whx进行合并成Wh,这样有利于统一矩阵运算。
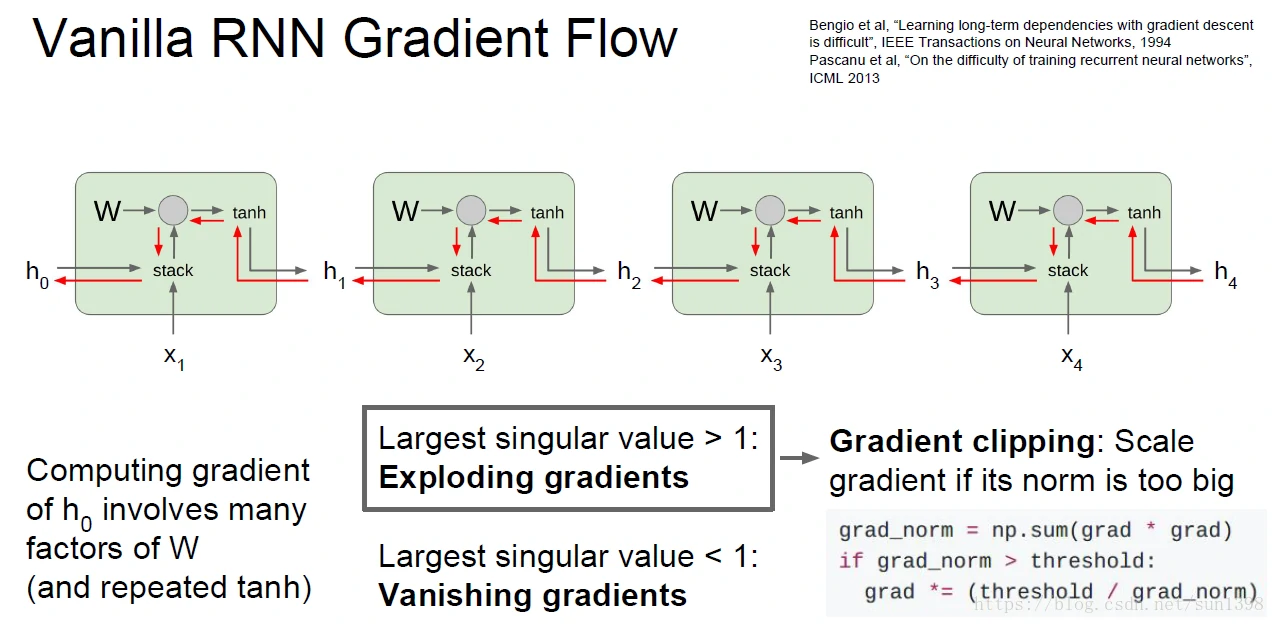
- 梯度爆炸设置阈值,梯度消失改变模型。
LSTM
- RNN存在一个非常大的缺陷,那就是长期依赖性的问题。比如在文本处理中,由于距离短,RNN语言的单复数的关联性还是存在的;但比如“我出生在美国亚利桑那州,现在住在纽约,我说英语”美国与英语的关联性在这么长的距离可能就会失去关联性。
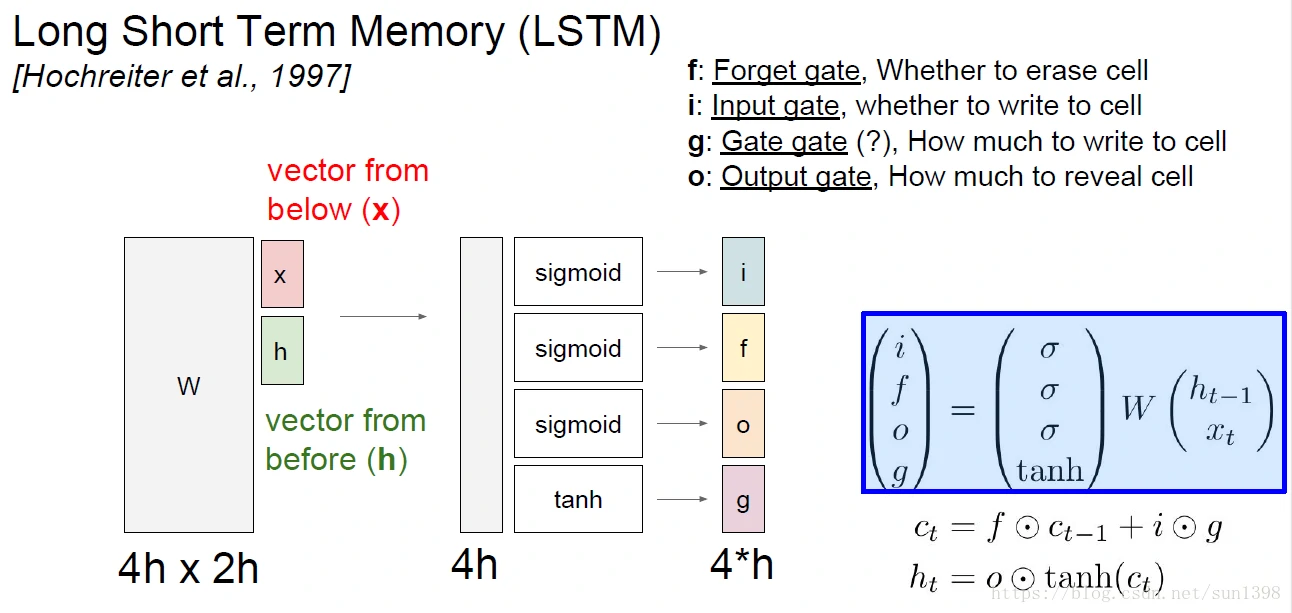
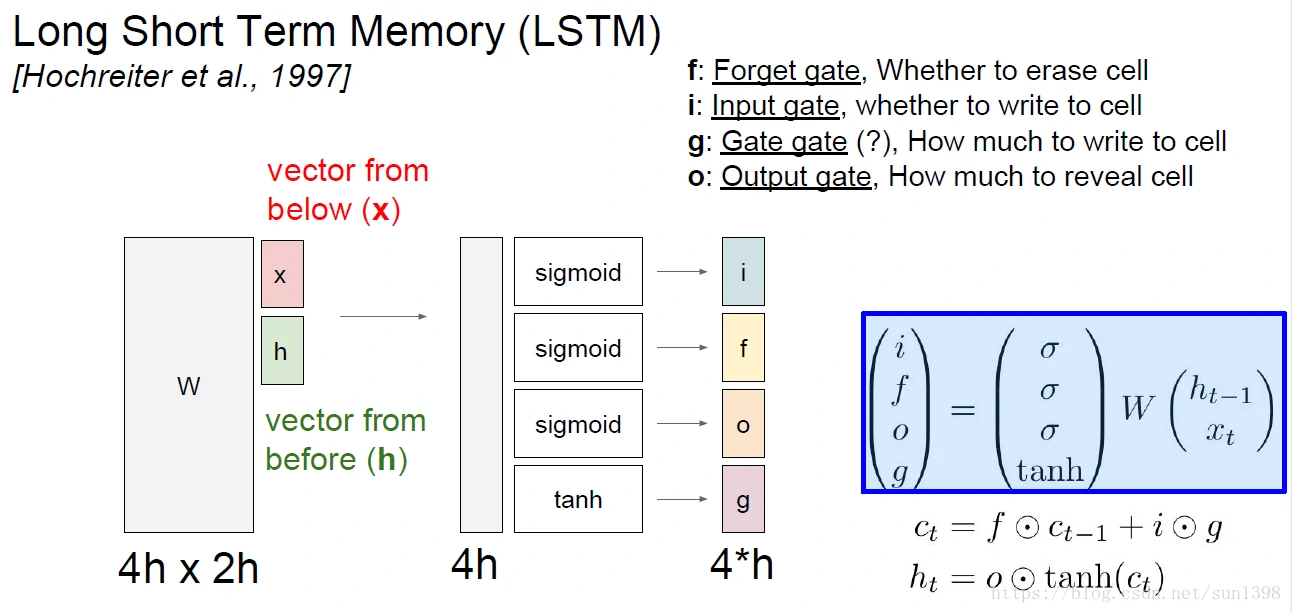
LSTM(Long Short Term):LSTM 通过刻意的设计来避免长期依赖问题,LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互,信息在状态更新上。
LSTM设计上存在四个门:i(input)、f(forget)、o(output)、g(gate)。其中i/f/o为sigmoid门,范围为(0-1),门控用来更新不同的状态;g门用来根据隐藏状态h和输入x更新细胞状态的主要内容,严格来说g应该算门,应该是状态。
f门用来表征细胞状态被遗忘多少,0完全遗忘、1完全保留;i门和g状态将当前的状态更新到细胞状态中,可能增加了输入的一些要长期保存的特征。将当前细胞状态经过tanh的激活以后,通过o门更新为隐藏状态h。
实际上h与c的相似性比较大,总觉得整个单元结果存在很大的冗余性,而且这样操作隐藏状态h的作用没有发挥的太大,但这是多样性的一个体现。
LSTM存在一个特点:只使用一组权重W进行更新,也不好说是优点还是缺点。
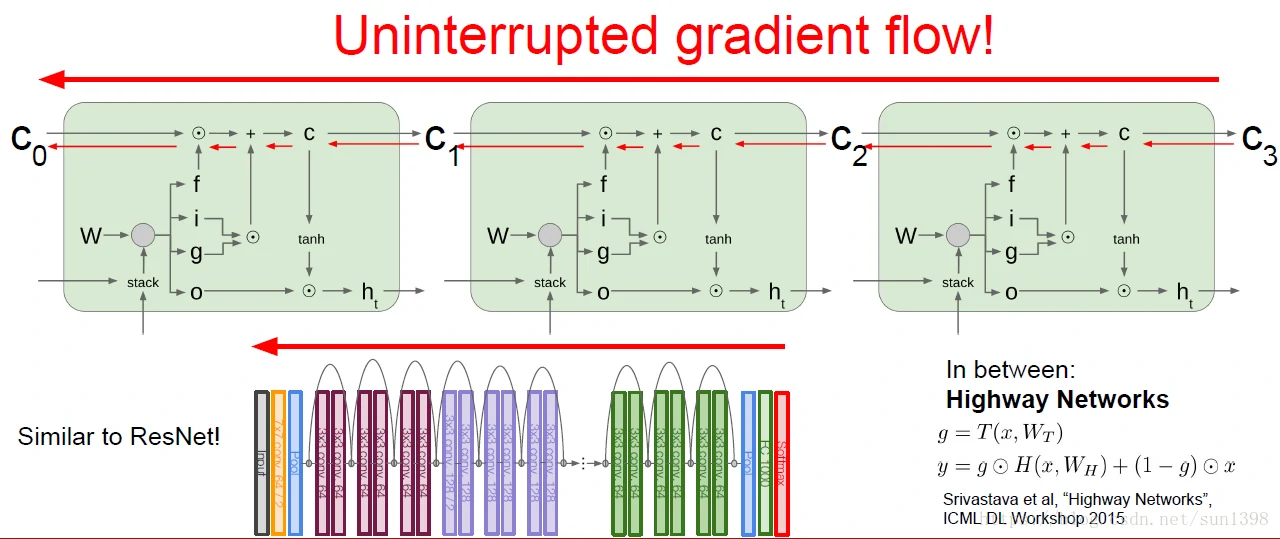
- 反向传播对于细胞状态的更新可以实现在整个网络中进行,形成完整的梯度流。
GRU

GRU作为LSTM的一个变种,将隐藏状态和细胞状态结合在一起,降低了单元的冗余度,整个单元变得更加简单。
不用在将LSTM的多种门结合到GRU中来解释,r和z都起到了记忆和遗忘作用,将过去的隐藏状态更新到了当前状态。z决定了最终更新是遗忘过去更多,还是忽略当前更多,这是一个概率为1的互补事件。而在当前的临时状态中,r也起到了对过去隐藏状态的保留程度。因此在
与LSTM相比,GRU有3组权重待更新,对于细胞状态中,权重用来表征选择,相当于增加网络的多样性,用来选择对长短期效应的记录,感觉会更加完善,但是如果一组权重就够用,这也就变成冗余性。与LSTM类似,这是一个互补。
每一种LSTM及其变种之间的效率都差别不大,通用型都差不多,但是各自可能有各自的最合适的情况,很难评定谁更优,除非出现一种新的结构,而不是简单的改变。