原文
今天介绍一篇OpenAI的神作CLIP,文章发表在ICML-2021,于2021年3月挂在arXiv上的。
论文链接:https://arxiv.org/pdf/2103.00020.pdf
Blog传送门:https://openai.com/blog/clip/
Code传送门:https://github.com/openai/CLIP
Abstract
(此部分翻译为主)
当前的计算机视觉(CV)模型通常被训练用于预测有限的物体类别。这种严格的监督训练方式限制了模型的泛化性和实用性,因为这样的模型通常还需要额外的标注数据来完成训练时未曾见过的视觉“概念”。直接从图片的描述文本中学习是一个有潜力的选择,因为这样我们可以获取更多的监督信号。这篇文章中,我们证明了利用一个简单的预训练任务(即预测哪个文本描述对应当前图像)在一个从互联网上搜集的4亿个(图像,文本)对的数据集上可以取得SOTA的图像表征。预训练完之后,在下游任务上,我们可以通过用自然语言(文本)匹配视觉概念(图像)从而实现zero-shot transfer。我们在30个不同类型的下游CV任务上进行了基准测试,并展示了我们模型强大的迁移能力,其在很多下游任务上不需要任何额外的数据也能比拟完全supervised的模型。比如,我们的模型在ImageNet上的zero-shot accuracy能达到在ImageNet上全监督训练的ResNet-50的性能。
Motivation
在NLP中,预训练的方法目前其实已经被验证很成功了,像BERT和GPT系列之类的。其中,GPT-3从网上搜集了400 billion byte-pair-encoded tokens进行预训练然后可以在很多下游任务上实现SOTA性能和zero-shot learning。这其实说明从web-scale的数据中学习是可以超过高质量的人工标注的NLP数据集的。
然而,对于CV领域,目前预训练模型基本都是基于人工标注的ImageNet数据集(含有1400多万张图像),那么借鉴NLP领域的GPT-3从网上搜集大量数据的思路,我们能不能也从网上搜集大量图像数据用于训练视觉表征模型呢?
作者先是回顾了并总结了和上述相关的两条表征学习路线:
- 构建image和text的联系,比如利用已有的(image,text)pair数据集,从text中学习image的表征;
- 获取更多的数据(不要求高质量,也不要求full labeled)然后做弱监督预训练,就像谷歌使用的JFT-300M数据集进行预训练一样(在JFT数据集中,类别标签是有噪声的)。具体来说,JFT中一共有18291个类别,这能教模型的概念比ImageNet的1000类要多得多,但尽管已经有上万类了,其最后的分类器其实还是静态的、有限的,因为你最后还是得固定到18291个类别上进行分类,那么这样的类别限制还是限制了模型的zero-shot能力。
这两条路线其实都展现了相当的潜力,前者证明paired text-image可以用来训练视觉表征,后者证明扩充数据能极大提升性能,即使数据有noise。于是high-level上,作者考虑从网上爬取大量的(text,image)pair以扩充数据,同时这样的pairs是可以用来训练视觉表征的。作者随即在互联网上采集了4亿个(text,image)对,准备开始训练模型。
Model
Objective
海量的(image,text)数据有了,问题是怎么设计并高效地训练模型。作者提出CLIP的模型,可以认为是ConVIRT[1]的简化版。这里先简单回顾下ConVIRT (咋一看是不是觉得CLIP和ConVIRT一模一样)
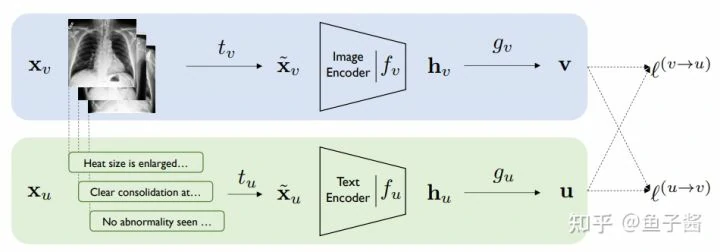
VonVIRT用(image,text)对来训练模型,其有一个image encoder和一个text encoder,训练目标是让两路的representation尽可能得一致(对偶地最大化表征的agreement),其中gv和gu函数是一个non-linear得projection head,负责分别将图像和文本表征投影到一个shared的空间,从而计算距离。
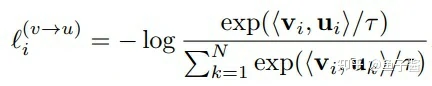
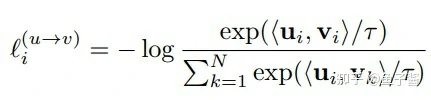
其实就是构造了一个对称的contrastive loss,在一个batch内预测谁是正样本。
基于ConVIRT,CLIP主要做出了以下简化:
- ConVIRT中的image encoder的参数是ImageNet初始化的,而CLIP直接用random初始化
- ConVIRT的projection head是non-linear的,而CLIP采用linear的projection
- CLIP去掉了ConVIRT中text transformation(指均匀从text中采样句子),因为CLIP数据集中很多指出过一次的(image,text)
- CLIP的image transformation只用了resize和squared crop
- CLIP loss中的temperature参数τ是可学的
于是CLIP的预训练模型就有了:
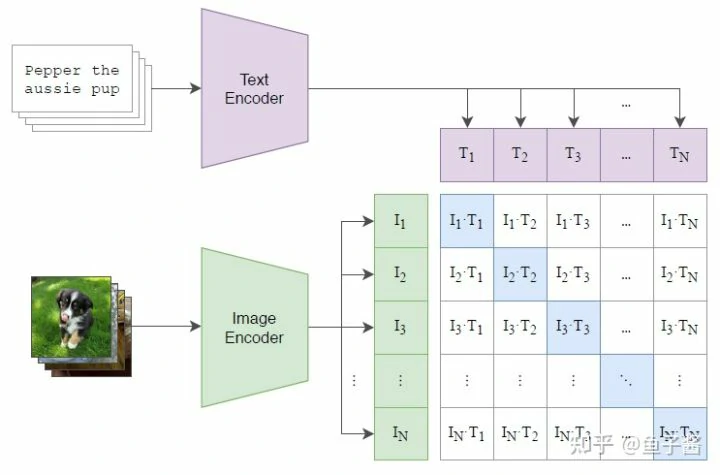
一个batch里有N对(image,text),然后和ConVIRT一样做对称的contrastive learning,伪代码如下:

Inference / Zero-shot prediction
一旦CLIP训练好了,我们就可以做zero-shot prediction了,如图所示:
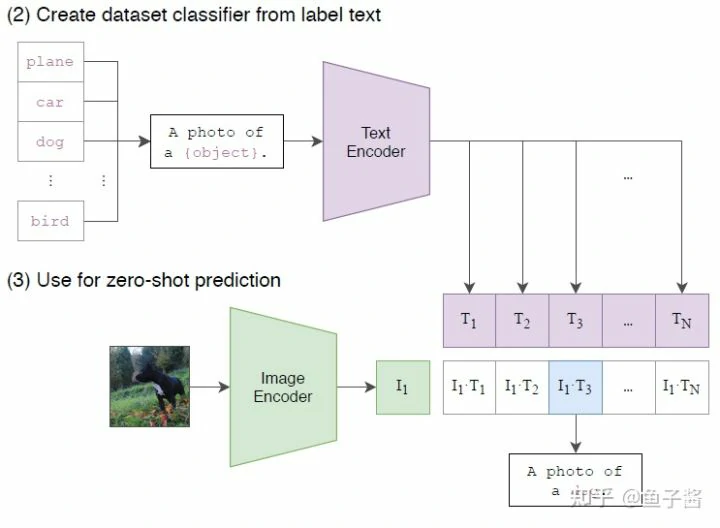
步骤可以整理成下面这样:
- Sample所有N个class,得到N个input text,都经过text encoder编码得到对应的N个class text embedding(我这里之所叫embedding而不叫representation是想说明这个特征是经过encoding和projection得到的)
- Sample一个要预测的image,得到其image embedding
- 以N个text embedding为key,以当前image embedding为query,算cosine相似度,相似度最高的即为Top-1的prediction class
预测过程的代码如下:
1 | import os |
Training
text encoder
作者统一采用GPT-2里的Transformer(63M-parameter 12-layer 512-wide model with 8 attention heads)。输入句子的最大长度为76。
image encoder
这里作者一共训练了8个不同的image encoder(5 ResNets & 3 ViTs),分别如下:
1 | _MODELS = { |
其中ResNets做了一个小的修改:将ResNet编码出来的结果再经过一个attention pooling(比如一个2048x7x7的feature,用attention pooling成一个2048x1的feature);对于ViTs也做了一个小的修改:在tokens(patch tokens和pos tokens相加)被送到Transformer之前,让tokens先经过一个layer norm层,此外参数的初始化和原来的ViTs也有微小的不同。
Other configuration
- optimizer:Adam
- training epochs:32
- batch size:32768
- precision:half-precision
Experiment
实验部分这里重点focus在CV相关部分。
Zero-shot CLIP v.s. Linear Probe on ResNet50
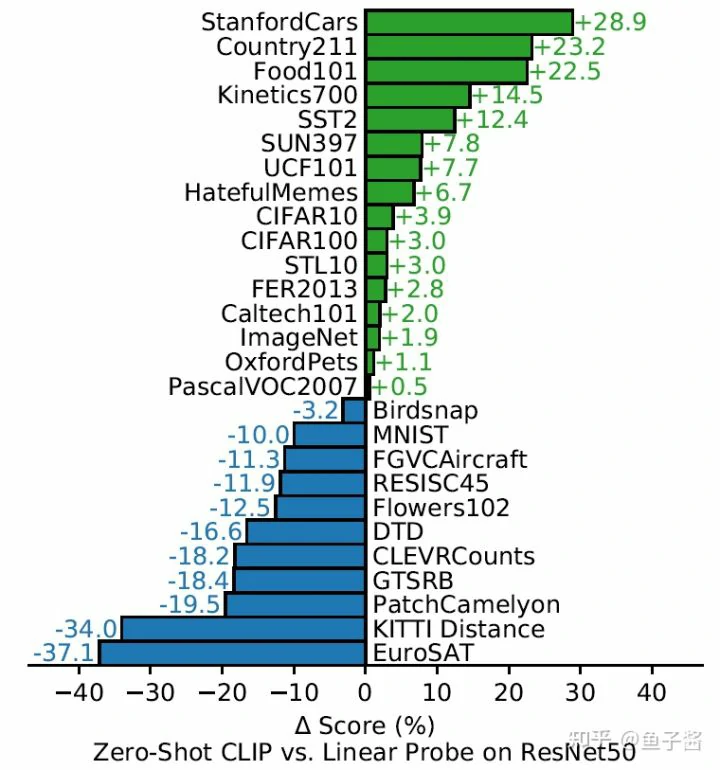
CLIP的胜率在16/27,已经很强了,因为CLIP是zero-shot的,即没有用下游任务的数据,而linear probed ResNet50用了下游数据进行finetune逻辑回归分类器的参数。
Prompt engineering and ensembling
作者默认prompt模板是:”A photo of a {label}.”,但作者发现这样的模板还是有点粗糙,可以考虑加一些context比如”A photo of a {label}, a type of pet.”。对于不同类型任务,作者做了一些手动的、特定的prompt工程。
从另一个角度,一张图的text描述其实有很多种的,只要text的核心语义和image相同就行,那么我们还可以做一些ensemble,比如ensemble一下”A photo of a big {label}.”和”A photo of a small {label}.”。
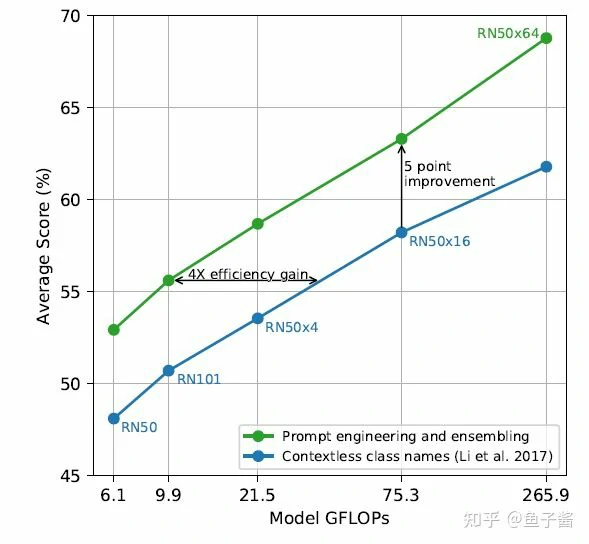
可以发现,采用Prompt engineering+ensembling的效果比只用没有上下文的类别名好得多。
(PS:作者这里的发现直接motivate了之后的CoOp[2],CoCoOp[3]之类learnable prompting的工作,后面有时间我会专门写一期关于这个的。)
Few-shot CLIP v.s. SOTA (ImageNet) SSL methods
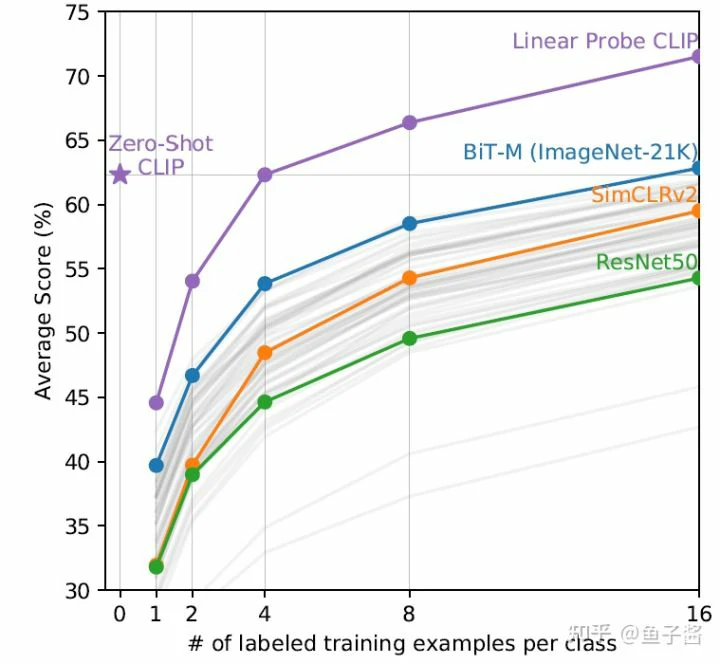
y: 20个测试数据集上的平均得分; x: shots
- Zero-shot CLIP的性能和4-shot CLIP差不多
- Few-shot CLIP的performance远高于之前的SOTA模型
How many shots is needed for achieving zero-shot performance
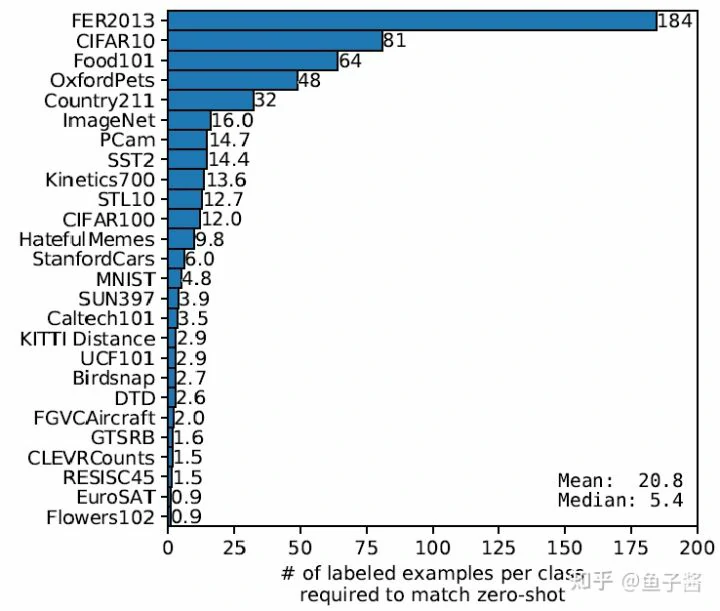
Few-shot (linear probing) CLIP (保持CLIP encoder 参数fixed,加一层逻辑回归分类器微调)平均需要20.8-shots才能match zero-shot CLIP性能。这里相当于保持了the same CLIP feature space上,观察few-shot finetuning和zero-shot的性能差异。这里其实说明通过自然语言学到的视觉概念比少量样本finetune学到的好。
Linear probing CLIP performance
这里不再是few-shot linear probing了,而是全量数据的linear probing,我们来看下其跟zero-shot性能的对比:
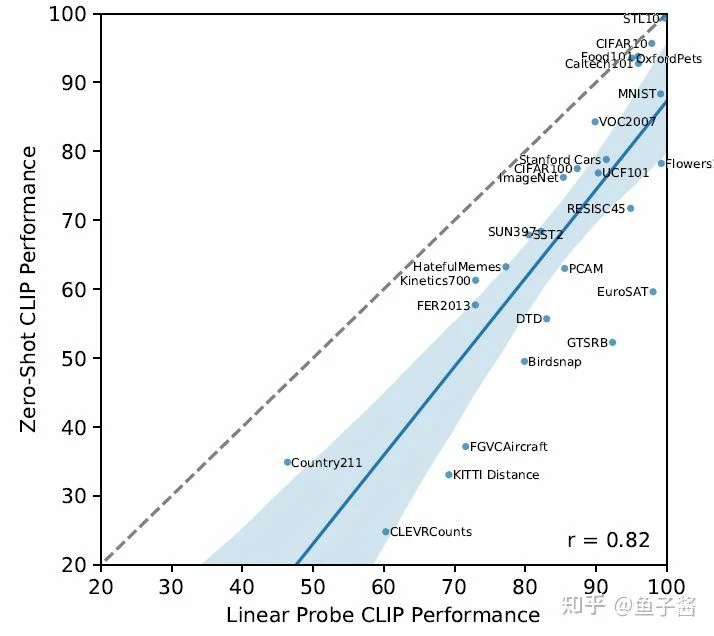
总体上,两者的性能是正相关的,此外,大部分情况下linear probing的性能要好不少。
再来一个linear probing的天梯图:
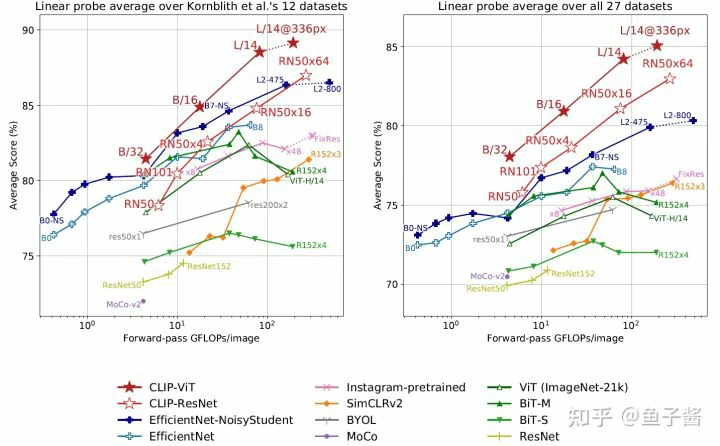
CLIP GOAT!!!
Robustness to Natural Distribution Shift
作者在ImageNet的7个shift datasets上观察各模型的平均性能。
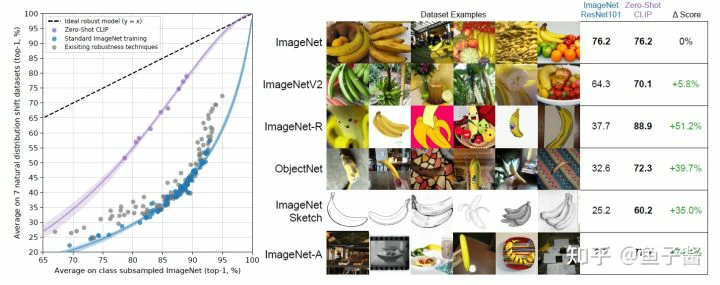
说实话,做domain adaptation(DA)/generalization(DG)的人看到这里应该挺兴奋,新的鲁棒特征来啦。不过问题来了,左边这张图是不是也反映了representation learning比DA、DG technique更重要呢?(那么,我们真的需要花那么大力气去卷DA嘛… 说不定通过这种大规模pretraining就能很大程度上解决domain shift的问题。但另一方面,DA、DG也可以在这些pretraining得到的表征上锦上添花。怎么说都有道理,但我更prefer to CLIP这类表征学习的意义。
CLIP的实验非常丰富,这里只是抛砖引玉地挑了几个我个人觉得比较有意思的实验讲,具体地还是推荐大家去看原文。
Limitation
这个部分往往容易被人忽略,但其实个人觉得,limitation和conclusion部分往往有作者们更深入的思考,这里简单总结下CLIP的limitation:
- CLIP的zero-shot性能虽然总体上比supervised baseline ResNet-50要好,但其实在很多任务上比不过SOTA methods,因此CLIP的transfer learning有待挖掘
- CLIP在这几种task上zero-shot性能不好:fine-grained分类(花的分类、车的分类之类的)、抽象的任务(如计算图中object的个数)以及预训练时没见过的task(如分出相邻车辆的距离)。BTW,在这些任务上zero-shot性能不好,不代表CLIP pretrained encoders就没用了,CLIP encoders还是能提供很强的视觉先验的
- Zero-shot CLIP在真正意义上的out-of-distribution data上性能不好,比如在OCR中
- 尽管CLIP zero-shot classifier能在很广泛的任务上work,但究其本质CLIP还是在有限的类别中进行对比、推理,而不能像image caption那样完全的flexible地生成新的概念(如:词),这是CLIP功能上的缺陷,CLIP终究不是生成模型
- CLIP仍然没有解决深度学习poor data efficiency的问题,结合CLIP和self-training可能是一个能提高data efficiency的方向
- CLIP的方法论上也存在几个缺陷:在训练和挑选CLIP模型时,作者采用在几个数据的validation performance来做指导,这其实是不准确的,因为它不能完全代表CLIP的zero-shot性能。如果,设计一套框架来evaluate zero-shot performance对于之后的研究是很重要的
- CLIP的训练数据是从网上采集的,这些image-text pairs没有做data clear和de-bias,这可能会使模型有一些social biases
- 很多视觉任务很难用text来表达,如何用更高效的few-shot learning方法优化CLIP也很重要
到此,CLIP基本讲完,总体来说,对于深度学习来说是优化时代意义的,这可能标志着我们即将迎来data-centric deep learning时代,印证了Andrew Ng的一句名言:“Your model is good enough. Foucs on the data!”(大概这个意思,词句不完全准确)。
参考链接
[1] Zhang Y, Jiang H, Miura Y, et al. Contrastive learning of medical visual representations from paired images and text[J]. arXiv preprint arXiv:2010.00747, 2020.
[2] Zhou K, Yang J, Loy C C, et al. Learning to prompt for vision-language models[J]. arXiv preprint arXiv:2109.01134, 2021.
[3] Zhou K, Yang J, Loy C C, et al. Conditional Prompt Learning for Vision-Language Models[J]. arXiv preprint arXiv:2203.05557, 2022.